文概览:介绍了kafka存储结构,以及kafka的生成者、消费者、broker集群、zookeeper四个组件。
1 kafka介绍
1.1 简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写。后来成为Apache软件基金会开源项目。它是一个发布与订阅消息系统,是系统架构中常用的MQ中间件。具有如下特点:
伸缩性。随着数据量增长,可以通过对broker集群水平扩展来提高系统性能。
高性能。通过横向扩展生产者、消费者(通过消费者群组实现)和broker(通过扩展实现系统伸缩性)可以轻松处理巨大的消息流。
消息持久化。基于磁盘的数据存储,消息不会丢失。
通过partion来实现多个生产者(同一个topic消息根据key放置到一个partion中)和多个消费者(一个partion由消费者群组中每一个消费者来负责)。
1.2 系统结构和存储结构
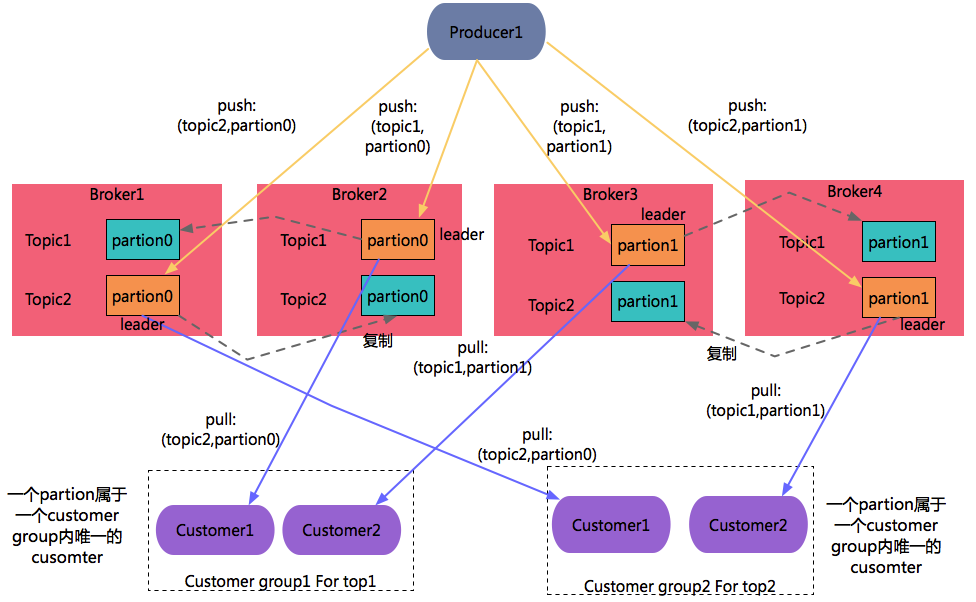
1、系统结构
producer采用push方式向broker发送消息。customer采用pull方式从broker接受消息。
- Producer:负责发布消息到 Kafka broker。
- Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
- Consumer Group:每个 Consumer 属于一个特定的 Consumer Group,若不指定 group name 则属于默认的 group。在同一个Group中,每一个customer可以消费多个Partion,但是一个partion只能指定给一个这个Group中一个Customer。
- Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker
2、关于一个Topic的物理存储结构
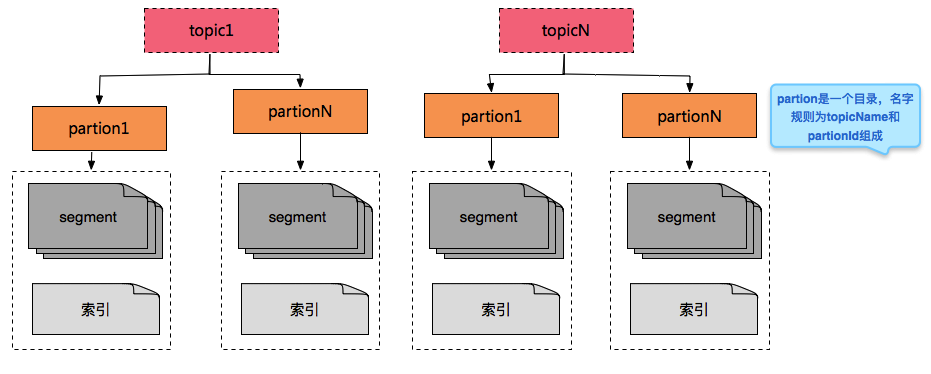
- Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
- Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
- Segment:是partion目录下的文件,保存存储消息。
- 索引:方便查询segment
3、segment文件格式
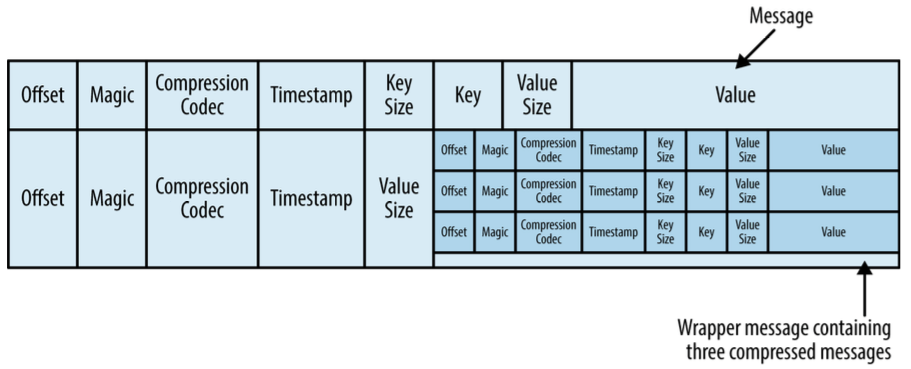
可以把topic当做一个数据表,表中每一个记录都是key,value形式,如下图。
注意: 必须要有一个key,如果没有,则默认会生成一个key,可以把key当做一个消息的标识,同一个key可能有多条数据。会使用key划分pation。
1.3 一些总结
1、一个主题存在多个分区,每一分区属于哪个leader broker?
在任意一个broker机器都有每一个分区所属leader的信息,所以可以通过访问任意一个broker获取这些信息。
2、每个消费者群组对应的分区偏移量的元数据存储在哪里。
最新版本保存在kafka中,对应的主题是_consumer_offsets。老版本是在zookeeper中。
3、假设某一个消息处理业务逻辑失败了。是否还可以继续想下执行?如果可以的话,那么此时怎么保证这个消息还会继续被处理呢?
答案是:正常情况下不会在处理有问题的消息。
这里举一个例子,如M1->M2->M3->M4,假设第一次poll时,得到M1和M2,M1处理成功,M2处理失败,我们采用提交方式为处理一个消息就提交一次,此时我们提交偏移量是offset1,但是当我们第二次执行poll时,此时只会获取到M3 和M4,因为poll的时候是根据本地便宜量来获取的,不是kafka中保存的初始偏移量。解决这个问题方法是通过seek操作定位到M2的位置,此时再执行poll时就会获取到M2和M3。
4、当一个消费者执行了close之后,此时会执行再均衡,那么在均衡是在哪里发生的呢?其他同组的消费者如何感知到?
是通过群组中成为群主的消费者执行再均衡,执行完毕之后,通过群组协调器把每一个消费者负责分区信息发送给消费者,每一个消费者只能知道它负责的分区信息。
5、如何保证时序性
因为kafkaf只保证一个分区内的消息才有时序性,所以只要消息属于同一个topic且在同一个分区内,就可以保证kafka消费消息是有顺序的了。
2 生产者
2.1 发送消息流程
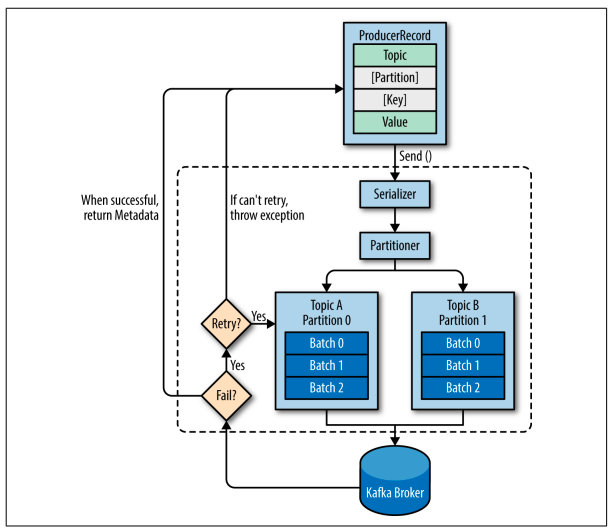
发送消息流程如下图,需要注意的有:
- 分区器Partitioner,分区器决定了一个消息被分配到哪个分区。在我们创建消息时,我们可以选择性指定一个键值key或者分区partion,如果传入的是key,则通过图中的分区器Partioner选择一个分区来保存这个消息;如果key和partion都没有指定,则会默认生成一个key。
- 批次传输。批次,就是一组消息,这些消息属于同一个主题和分区。发送时,会把消息分成批次Batch传输,如果每一个消息发送一次,会导致大量的网路开销,
- 如果消息成功写入kafka,就返回一个RecoredMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。
- 如果消息发送失败,可以进行重试,重试次数可以在配置中指定。
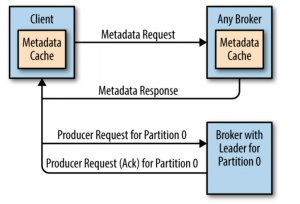
生产者在向broker发送消息时是怎么确定向哪一个broker发送消息?
- step1 :生产者客户端会向任一个broker发送一个元数据请求(MetadataRequest),获取到每一个分区对应的leader信息,并缓存到本地。
- step2:生产者在发送消息时,会指定partion或者通过key得到到一个partion,然后根据partion从缓存中获取相应的leader信息。
2.3 同步异步等三种方式解释
2.3.1 发送并忘记(fire-and-forget)
代码如下,直接通过send方法来发送
|
1 2 3 4 5 6 7 |
ProducerRecord<String, String> record = new ProducerRecord<>("CustomerCountry", "Precision Products", "France"); try { producer.send(record); } catch (Exception e) { e.printStackTrace(); } |
2.3.2 同步发送
代码如下,与“发送并忘记”的方式区别在于多了一个get()方法,会一直阻塞等待broker返回结果:
|
1 2 3 4 5 6 7 |
ProducerRecord<String, String> record = new ProducerRecord<>("CustomerCountry", "Precision Products", "France"); try { producer.send(record).get(); } catch (Exception e) { e.printStackTrace(); } |
2.3.3 异步发送
代码如下,异步方式相对于“发送并忘记”的方式的不同在于,在异步返回时可以执行一些操作,如记录错误或者成功日志。
首先,定义一个callback
|
1 2 3 4 5 6 7 8 |
private class DemoProducerCallback implements Callback { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) { e.printStackTrace(); } } } |
然后,使用这个callback
|
1 2 3 |
ProducerRecord<String, String> record = new ProducerRecord<>("CustomerCountry", "Biomedical Materials", "USA"); producer.send(record, new DemoProducerCallback()); |
3 消费者
3.1 消费者和消费者群组
3.1.1 消费者介绍
消费者以pull方式从broker拉取消息,消费者可以订阅一个或多个主题,然后按照消息生成顺序(kafka只能保证分区中消息的顺序)读取消息。
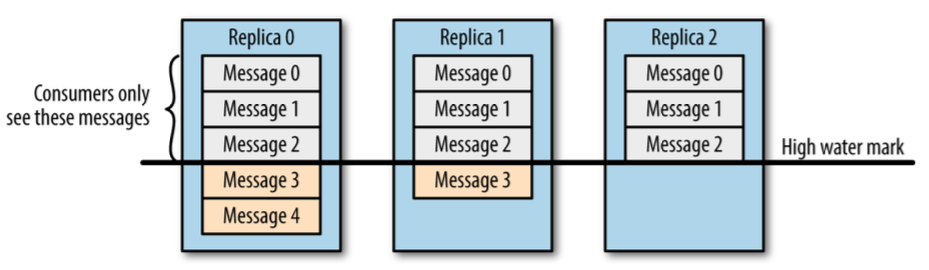
一个消息消息只有在所有跟随者节点都进行了同步,才会被消费者获取到。如下图,只能消费Message0、Message1、Message2:
3.1.2 消费者区组
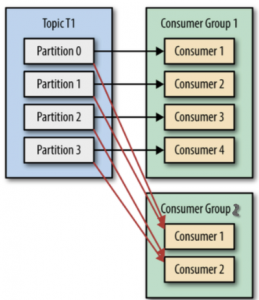
1、消费者群组
消费者群组可以实现并发的处理消息。一个消费者群组作为消费一个topic消息的单元,每一个partion只能隶属于一个消费者群组中一个customer,如下图
3.1.2 消费者区组的再均衡
当在群组里面 新增/移除消费者 或者 新增/移除 kafka集群broker节点 时,群组协调器Broker会触发再均衡,重新为每一个partion分配消费者。再均衡期间,消费者无法读取消息,造成整个消费者群组一小段时间的不可用。
- 新增消费者。customer订阅主题之后,第一次执行poll方法
- 移除消费者。执行customer.close()操作或者消费客户端宕机,就不再通过poll向群组协调器发送心跳了,当群组协调器检测次消费者没有心跳,就会触发再均衡。
- 新增broker。如重启broker节点
- 移除broker。如kill掉broker节点。
|
1 2 3 |
官网wiki: https://kafka.apache.org/documentation/ Consumer rebalancing is triggered on each addition or removal of both broker nodes and other consumers within the same group. |
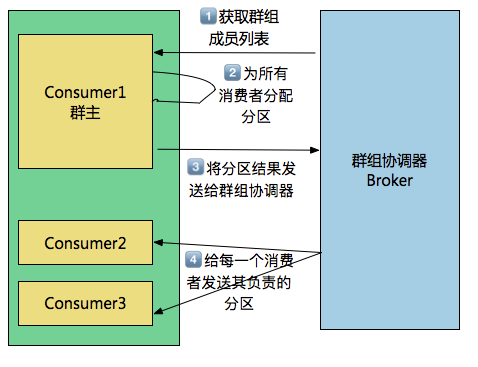
再均衡是是通过消费者群组中的称为“群主”消费者客户端进行的。什么是群主呢?“群主”就是第一个加入群组的消费者。消费者第一次加入群组时,它会向群组协调器发送一个JoinGroup的请求,如果是第一个,则此消费者被指定为“群主”(群主是不是和qq群很想啊,就是那个第一个进群的人)。
群主分配分区的过程如下:
step1:群主从群组协调器获取群组成员列表,然后给每一个消费者进行分配分区Partion。
stpp2:两个分配策略:Range和RoundRobin。
- Range策略,就是把若干个连续的分区分配给消费者,如存在分区1-5,假设有3个消费者,则消费者1负责分区1-2,消费者2负责分区3-4,消费者3负责分区5。
- RoundRoin策略,就是把所有分区逐个分给消费者,如存在分区1-5,假设有3个消费者,则分区1->消费1,分区2->消费者2,分区3>消费者3,分区4>消费者1,分区5->消费者2。
stpe3:群主分配完成之后,把分配情况发送给群组协调器。
stpe4:群组协调器再把这些信息发送给消费者。每一个消费者只能看到自己的分配信息,只有群主知道所有消费者的分配信息。
3.2 消费消息流程
3.2.1 消费流程demo
具体步骤如下
- step1 创建消费者。
- step2 订阅主题。除了订阅主题方式外还有使用指定分组的模式,但是常用方式都是订阅主题方式
- stpe3 轮询消息。通过poll方法轮询。
- stpe4 关闭消费者。在不用消费者之后,会执行close操作。close操作会关闭socket,并触发当前消费者群组的再均衡。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// 1.构建KafkaCustomer Consumer consumer = buildCustomer(); // 2.设置主题 consumer.subscribe(Arrays.asList(topic)); // 3.接受消息 try { while (true) { ConsumerRecords<String, String> records = consumer.poll(500); System.out.println("customer Message---"); for (ConsumerRecord<String, String> record : records) // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); } } finally { // 4.关闭消息 consumer.close(); } |
创建消费者的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public Consumer buildCustomer() { Properties props = new Properties(); // bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开 props.put("bootstrap.servers", "localhost:9092"); // 消费者群组 props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer <String, String>(props); return consumer; } |
3.2.2 消费消息方式
分为订阅主题和指定分组两种方式:
- 消费者分组模式。通过订阅主题方式时,消费者必须加入到消费者群组中,即消费者必须有一个自己的分组;
- 独立消费者模式。这种模式就是消费者是独立的不属于任何消费者分组,自己指定消费那些partion。
1、订阅主题方式
|
1 |
consumer.subscribe(Arrays.asList(topic)); |
2、独立消费者模式
通过consumer的assign(Collection<TopicPartition> partitions)方法来为消费者指定分区。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
/** * 独立消费者 */ public void consumeMessageForIndependentConsumer(String topic){ // 1.构建KafkaCustomer Consumer consumer = buildCustomer(); // 2.指定分区 // 2.1获取可用分区 List<PartitionInfo> partitionInfoList = buildCustomer().partitionsFor(topic); // 2.2指定分区,这里是指定了所有分区,也可以指定个别的分区 if(null != partitionInfoList){ List<TopicPartition> partitions = Lists.newArrayList(); for(PartitionInfo partitionInfo : partitionInfoList){ partitions.add(new TopicPartition(partitionInfo.topic(),partitionInfo.partition())); } consumer.assign(partitions); } // 3.接受消息 while (true) { ConsumerRecords<String, String> records = consumer.poll(500); System.out.println("consume Message---"); for (ConsumerRecord<String, String> record : records) { // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 异步提交 consumer.commitAsync(); } } } |
3.2.3 轮询获取消息
通过poll来获取消息,但是获取消息时并不是立刻返回结果,需要考虑两个因素:
- 消费者通过customer.poll(time)中设置的等待时间
- broker会等待累计一定量数据,然后发送给消费者。这样可以减少网络开销。
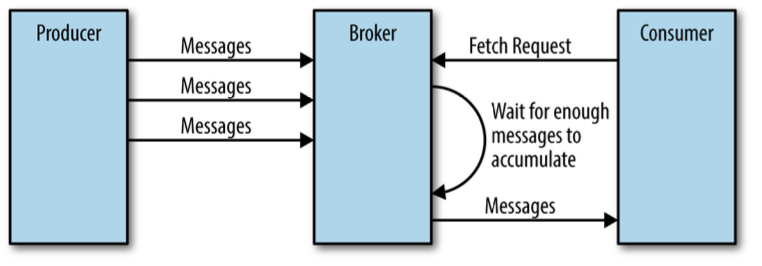
poll除了获取消息外,还有其他作用,如下:
- 发送心跳信息。消费者通过向被指派为群组协调器的broker发送心跳来维护他和群组的从属关系,当机器宕掉后,群组协调器触发再分配
3.3 提交偏移量
3.3.1 偏移量和提交
1、偏移量
偏移量offeset,是指一个消息在分区中位置。在通过生产者向kafka 推送消息返回的结果中包含了这个偏移量值,或者在消费者拉取信息时,也会包含消息的偏移量信息。
2、提交的解释
我们把消息的偏移量提交到kafka的操作叫做提交或提交偏移量。
3、偏移量的应用
目前会有两个位置记录这个偏移量:
(1)kafka broker保存。消费者通过提交操作,把读取分区中最新消息的偏移量更新到kafka服务器端(老版本的kafka是保存在zookeeper中),即消费者往一个叫做_consumer_offset的特殊主题发送消息,消息里面包消息的偏移量信息,并且该主题配置清理策略是compact,即对于每一个key只保存最新的值(key由groupId、topic和partition组成)。关于提交操作在本节进行讨论。
如果消费者一直处于运行状态,这个偏移量是没有起到作用,只有当加入或者删除一个群组里消费者,然后进行再均衡操作只有,此时为了可以继续之前工作,新的消费者需要知道上一个消费者处理这个分区的位置信息。
(2)消费者客户端保存。消费者客户端会保存poll()每一次执行后的最后一个消息的偏移量,这样每次执行轮询操作poll时,都从这个位置获取信息。这个信息修改可以通过后续小节中三个seek方法来修改。
4、提交时会遇到两个问题
(1) 重复处理
当提交的偏移量小于客户端处理的最后一个消息的偏移量时,会出现重复处理消息的问题,如下图
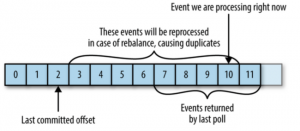
(2)消息丢失
当提交的偏移量大于客户端处理的最后端最后一个消息的偏移量,会出现消息丢失的问题,如下图:
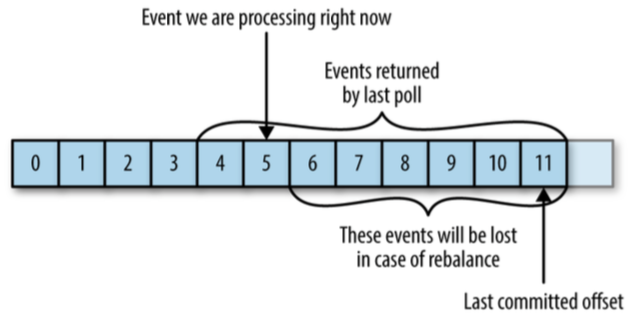
5、提交方式
主要分为:自动提交和手动提交。
(1)自动提交
auto.commit.commit ,默认为true自动提交,自动提交时通过轮询方式来做,时间间通过auto.commit.interval.ms属性来进行设置。
(2)手动提交
除了自动提交,还可以进行手动提交,手动提交就是通过代码调用函数的方式提交,在使用手动提交时首先需要将auto.commit.commit 设置为false,目前有三种方式:同步提交、异步提交、同步和异步结合。
3.3.2 同步提交
可以通过commitSync来进行提交,同步提交会一直提交直到成功。如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
/** * 手动同步提交 * * @param topic */ public void customerMessageWithSyncCommit(String topic) { // 1.构建KafkaCustomer Consumer consumer = buildCustomer(); // 2.设置主题 consumer.subscribe(Arrays.asList(topic)); // 3.接受消息 while (true) { ConsumerRecords<String, String> records = consumer.poll(500); System.out.println("customer Message---"); for (ConsumerRecord<String, String> record : records) { // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 同步提交 try { consumer.commitSync(); } catch (Exception e) { logger.error("commit error"); } } } } |
3.5.3 异步提交
同步提交一个缺点是,在进行提交commitAysnc()会阻塞整个下面流程。所以引入了异步提交commitAsync(),如下代码,这里定义了OffsetCommitCallback,也可以只进行commitAsync(),不设置任何参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
/** * 手动异步提交 * * @param topic */ public void customerMessageWithAsyncCommit(String topic) { // 1.构建KafkaCustomer Consumer consumer = buildCustomer(); // 2.设置主题 consumer.subscribe(Arrays.asList(topic)); // 3.接受消息 while (true) { ConsumerRecords<String, String> records = consumer.poll(500); System.out.println("customer Message---"); for (ConsumerRecord<String, String> record : records) { // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 异步提交 consumer.commitAsync(new OffsetCommitCallback() { public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) { if (e != null) { logger.error("Commit failed for offsets{}", offsets, e); } } }); } } } |
2.3.4 同步和异步提交组合
代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/** * 使用同步和异步提交 * * @param topic */ public void customerMessageWithSyncAndAsyncCommit(String topic) { // 1.构建KafkaCustomer Consumer consumer = buildCustomer(); // 2.设置主题 consumer.subscribe(Arrays.asList(topic)); // 3.接受消息 try { while (true) { ConsumerRecords<String, String> records = consumer.poll(500); System.out.println("customer Message---"); for (ConsumerRecord<String, String> record : records) { // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 异步提交 consumer.commitAsync(); } } } catch (Exception e) { } finally { // 同步提交 try { consumer.commitSync(); } finally { consumer.close(); } } } |
3.6从指定偏移量获取数据
我们读取消息是通过poll方法。它根据消费者客户端本地保存的当前偏移量来获取消息。如果我们需要从指定偏移量位置获取数据,此时就需要修改这个值为我们想要读取消息开始的地方,目前有如下三个方法:
- seekToBeginning(Collection<TopicPartition> partitions)。可以修改分区当前偏移量为分区的起始位置、
- seekToEnd(Collection<TopicPartition> partitions)。可以修改分区当前偏移量为分区的末尾位置
- seek(TopicPartition partition, long offset); 可以修改分区当前偏移量为分区的起始位置
通过seek(TopicPartition partition, long offset)可以实现处理消息和提交偏移量在一个事务中完成。思路就是需要在可短建立一个数据表,保证处理消息和和消息偏移量位置写入到这个数据表在一个事务中,此时就可以保证处理消息和记录偏移量要么同时成功,要么同时失败。代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
consumer.subscribe(topic); // 1.第一次调用pool,加入消费者群组 consumer.poll(0); // 2.获取负责的分区,并从本地数据库读取改分区最新偏移量,并通过seek方法修改poll获取消息的位置 for (TopicPartition partition: consumer.assignment()) consumer.seek(partition, getOffsetFromDB(partition)); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { processRecord(record); storeRecordInDB(record); storeOffsetInDB(record.topic(), record.partition(), record.offset()); } commitDBTransaction(); } |
4 Broker集群
4.1 集群控制器
控制器除了具有一般broker的功能,还负责分区leader的选举。
4.2 分区 leader 和 follower
Kafka在0.8以前的版本中,如果一个broker机器宕机了,其上面的partion都不能用了。为了实现High Availablity,引入了复制功能,即一个partion还会在其他的broker上面进行备份。为了实现复制功能,引入了分区leader和follower:
(1)Leader作用
生产者和消费者请求都会经过这个leader。Producer和Concumer往一个partion写入和读取消息时,都会首先查找这个partion的leader
保存那些follower节点的状态与自己是一致的。
(2)follower作用:
定时通过类似消费者的poll方法从leader中获取消息,进行备份
同一个topic的不同partion会分布在多个broker上,而且一个partion还会在其他的broker上面进行备份,Producer在发布消息到某个Partition时,先找到该Partition的Leader,然后向这个leader推送消息;每个Follower都从Leader 拉取消息,拉取消息成功之后,向leader发送一个ack确认。如下一个流程图,
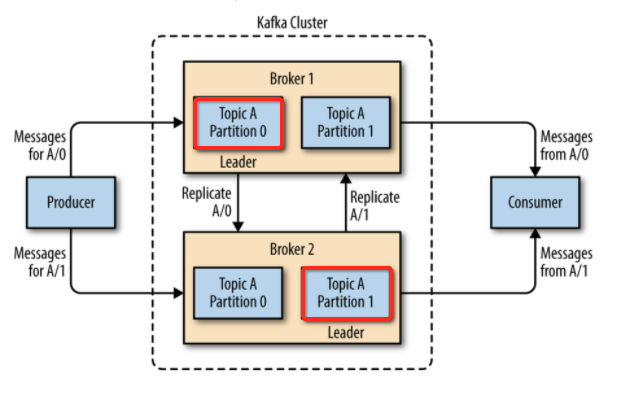
4.3 群组协调器
群组协调器,顾名思义就是维护消费者群组 ,消费者通过向被指派为群组协调器的broker(不同的群组可以有不同的协调器)发送心跳来维护它们和群组的从属关系,以及它们对分区的所有权。
1、触发再均衡
只要消费者以正常的时间间隔发送心跳,就会被认为是活跃的。消费者是通过poll获取消息时,发送的心跳的,当消费者客户端宕机之后,群组协调器在一段内没有收到心跳,则此时会认为消费者已死亡,然后触发一次再均衡。具体再均衡流程,可以参考上面的“再均衡”小节。
5 Zookeeper集群
5.1 节点信息
参考:https://cwiki.apache.org/confluence/display/KAFKA/Kafka+data+structures+in+Zookeeper
Zookeeper保存的就是节点信息和节点状态,不会保存kafka的消息信息,节点信息包括:
1、broker。
broer启动时在zookeeper注册、并通过watcher监听broker节点变化,用来管理kafka集群。
2、Topic信息
- 主题相关配置信息,如主题的复制个数、分区个数
- 主题的各个分区信息,选举每一个分区的leader。维护分区的leader和follower的broker信息。
3、consumers
- 消费者节点信
4、admin
5、config
6、controller和controloer_epoch
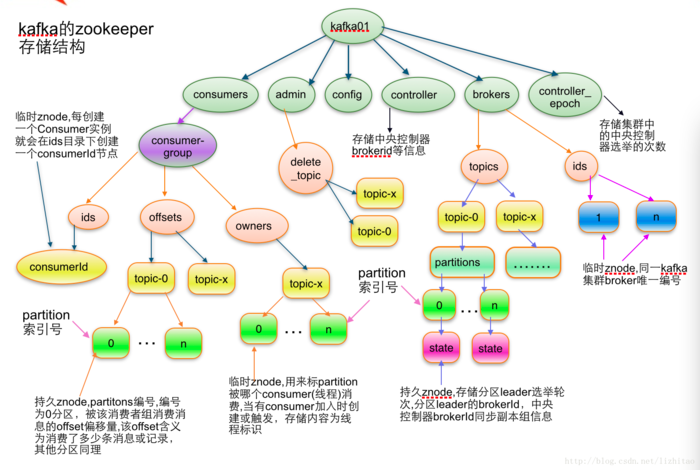
5.1. 1 broker
1、Topic的注册信息
作用:在创建zookeeper时,注册topic的partion信息,包括每一个分区的复制节点id。
路径:/brokers/topics/[topic]
数据格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Schema: { "fields" : [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "partitions", "type": {"type": "map", "values": {"type": "array", "items": "int", "doc": "a list of replica ids"}, "doc": "a map from partition id to replica list"}, } ] } Example: { "version": 1, "partitions": {"0": [0, 1, 3] } } # 分区0的对应的复制节点是0、1、3. } |
2、分区信息
作用:记录分区信息,如分区的leader信息
路径信息:/brokers/topics/[topic]/partitions/[partitionId]/state
格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "isr", "type": {"type": "array", "items": "int", "doc": "an array of the id of replicas in isr"} }, {"name": "leader", "type": "int", "doc": "id of the leader replica"}, {"name": "controller_epoch", "type": "int", "doc": "epoch of the controller that last updated the leader and isr info"}, {"name": "leader_epoch", "type": "int", "doc": "epoch of the leader"} ] } Example: { "version": 1, "isr": [0,1], "leader": 0, "controller_epoch": 1, "leader_epoch": 0 } |
3 broker信息
作用:在borker启动时,向zookeeper注册节点信息
路径:/brokers/ids/[brokerId]
数据格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "host", "type": "string", "doc": "ip address or host name of the broker"}, {"name": "port", "type": "int", "doc": "port of the broker"}, {"name": "jmx_port", "type": "int", "doc": "port for jmx"} ] } Example: { "version": 1, "host": "192.168.1.148", "port": 9092, "jmx_port": 9999 } |
5.1.2 controller和controller_epoch
1、 控制器的 epoch:
/controller_epoch -> int (epoch)
2、控制器的注册信息:
/controller -> int (broker id of the controller)
5.1.3 consumer
1.消费者注册信息:
路径:/consumers/[groupId]/ids/[consumerId]
数据格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
Schema: { "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "pattern", "type": "string", "doc": "can be of static, white_list or black_list"}, {"name": "subscription", "type" : {"type": "map", "values": {"type": "int"}, "doc": "a map from a topic or a wildcard pattern to the number of streams"} } ] } Example: A static subscription: { "version": 1, "pattern": "static", "subscription": {"topic1": 1, "topic2": 2} } A whitelist subscription: { "version": 1, "pattern": "white_list", "subscription": {"abc": 1} } A blacklist subscription: { "version": 1, "pattern": "black_list", "subscription": {"abc": 1} } |
onsumers/[groupId]/owners/[topic]/[partitionId] -> string (consumerId)
3. Consumer offset:
/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset)
5.1.4 admin
1. Re-assign partitions
路径:/admin/reassign_partitions
数据格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition to be reassigned" }, { "name":"partition", "type":"int", "doc":"the partition to be reassigned" }, { "name":"replicas", "type":"array", "items":"int", "doc":"a list of replica ids" } ], } "doc":"an array of partitions to be reassigned to new replicas" } } ] } Example: { "version": 1, "partitions": [ { "topic": "Foo", "partition": 1, "replicas": [0, 1, 3] } ] } |
2. Preferred replication election
路径:/admin/preferred_replica_election
数据格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
{ "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition for which preferred replica election should be triggered" }, { "name":"partition", "type":"int", "doc":"the partition for which preferred replica election should be triggered" } ], } "doc":"an array of partitions for which preferred replica election should be triggered" } } ] } Example: { "version": 1, "partitions": [ { "topic": "Foo", "partition": 1 }, { "topic": "Bar", "partition": 0 } ] } |
3. Delete topics
/admin/delete_topics/[topic_to_be_deleted] (the value of the path in empty)
5.1.5 config
1 Topic Configuration
/config/topics/[topic_name]
数据格式:
|
1 2 3 4 5 6 7 8 |
{ "version": 1, "config": { "config.a": "x", "config.b": "y", ... } } |
5.2 zookeeper一些总结
离开了Zookeeper, Kafka 不能对Topic 进行新增操作, 但是仍然可以produce 和consume 消息.
6 相关属性
6.1 kafka 生产者
生产者相关配置如下:
| Configuration Settings | Description |
| client.id | identifies producer application |
| producer.type | either sync or async |
| acks | The acks config controls the criteria under producer requests are con-sidered complete.
-1 和 all意义一样。 |
| min.insync.replicas | 和acks=all一起使用 |
| retries | If producer request fails, then automatically retry with specific value. |
| bootstrap.servers | bootstrapping list of brokers. |
| linger.ms | if you want to reduce the number of requests you can set linger.ms to something greater than some value. |
| key.serializer | Key for the serializer interface. |
| value.serializer | value for the serializer interface. |
| batch.size | Buffer size. |
| buffer.memory | controls the total amount of memory available to the producer for buff-ering. |
1、关于request.required.acks 和 acks关系
In Kafka 0.9, request.required.acks=-1 which configration of producer is replaced by acks=all, but this old config is remained in docs.
request.required.acks各个值如下:
- 0。表示不需要broker确认消息是否写入。不需要leader和follwer确认。
- 1。只需要leader确认消息成功,不需要follwer确认。
- -1 。不进行需要leader确认,而且需要所有follwer的确认,才表示消息写入成功
2、min.insync.replicas
需要和使用 request.required.acks=-1 一起使用。
(1)介绍
当producer设置request.required.acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer会产生异常。如果我们设置的min.insync.replicas的值大于副本数时,此时在写入消息时,会报如下错误
org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
(2)min.insync.replicas作用
是为了保证一个消息必须有n个副本。举例,比如设置副本数是2,假设有两个broker,此时有一个broker挂掉了,对于一个消息此时只会有一份数据了。如果不设置min.insync.replicas,只是设置request.required.acks=-1,无法察觉这个broker关掉的问题(因为现在只有一个broker,所以只要接受到leader确认,就表示所有消息都确认了),但是如果设置了min.insync.replicas=2,此时就会报错了。
6.2 topic
| 属性 | 描述 |
| patitions | 分区个数 |
| replication.factor | 备份个数。复制系数 |
6.3 kafka 消费者
消费者相关配置如下
| Configuration Settings | Description |
| bootstrap.servers | Bootstrapping list of brokers. |
| group.id | Assigns an individual consumer to a group. |
| enable.auto.commit | Enable auto commit for offsets if the value is true, otherwise not committed. |
| auto.commit.interval.ms | Return how often updated consumed offsets are written to ZooKeeper. |
| session.timeout.ms | Indicates how many milliseconds Kafka will wait for the ZooKeeper to respond to a request (read or write) before giving up and continuing to consume messages. |
|
max.poll.interval.ms |
消费者不间断的调用poll()。如果长时间没有调用poll,且间隔超过这个值时,就会认为这个consumer失败了。然后执行reblance。 |
6.4 kafka server端-broker集群
| 属性 | 描述 |
| default.replication.factor | 备份个数。复制系数 |
| num.partitions | topic的默认分区个数 |
|
min.insync.replicas |
|
| broker.id | |
| log.dirs | 地址路径 |
| zookeeper.connect | zookeer集群地址,多个使用逗号隔开 |
- 建议1 关于kafka备份个数和topic分区个数建议都使用kafka集群的配置,不再创建topic时通过topic属性来指定,这样方便管理。
7 kafka新特性
在Kafka 0.11.0.0引入了EOS(exactly once semantics,精确一次处理语义)的特性,这个特性包括kafka幂等性和kafka事务两个属性。参考:
8 参考资料
1、官网文档:https://kafka.apache.org/documentation
2、《Kafka The Definitive Guide》
3、kafka在zookeer保存数据结构 https://cwiki.apache.org/confluence/display/KAFKA/Kafka+data+structures+in+Zookeeper