本文概览:介绍了实现同步器的unSafe和Locksuport两个技术;介绍AQS两个模式对应的接口,如acquire/release、acquireShard/releaseShard ;还利用AbstractQueueSynchronizer来自己设计一个锁。
1 同步器介绍
同步器可以看出是一个资源管理器,线程可以根据同步器来获取和释放资源。它定义了线程对资源(一个实例对象就是一个资源,一段代码也是一个资源)是否能够获取以及线程的排队等操作,它有一个FIFO对列用来存放线程的信息。同步器有排他和共享两个模式。
1.1 实现同步器的两个技术
主要通过如下两个操作来实现:
(1)通过unSafe来()更新线程间共享变量,如state,变量类型都是volatitle类型
UnSafe是为了保证多个线程同时更新一个共享变量。
(2)通过LockSupport#park()和LockSupport#unpark来协调进程执行顺序。
这两个技术还会在后面章节进行介绍。
1.2 入口
1、 同步器的四个核心接口,分为共享模式和排它模式
(1)排他模式
在同一时刻,只准许一个线程来使用(就是说这个资源只准许一个线程访问),当有多个线程时,需要放在线程等待对列中。所以就需要在同步器中定义一个状态表里,来描述同步器的状态,看看这个同步器对应的资源是否被线程占用。对应接口:
- acquired
- release
(2)共享模式
对于多个线程获取都可以成功。对应接口为:
- acquireShared
- releaseShared
(3)共享模式与排他模式的区别
共享模式与排他模式区别可以体现在acquireShared中的setHeadAndProgate的拓展性,即如果下一个节点是读节点就释放此线程节点。当一个共享模式线程节点被激活之后,通过setHeadAndPropagate来实现扩散性。
2、 同步器其他接口,也分为共享模式和排它模式
(1)排他模式
- tryAcquireNanos(int arg,long nanosTimeout),实现
ReentrantLock/WriteLock 的tryLock(time)接口,当超过等待时间,返回false。
- acquireInterruptibly(inte arg),实现ReentrantLock/WriteLock 的 lockInterruptibly接口。引入目的就是为了响应中断:
|
1 2 3 4 5 6 7 8 9 10 |
public final void acquireInterruptibly(int arg) throws InterruptedException { //1. 在获取同步器前,如果中断就抛出异常 if (Thread.interrupted()){ throw new InterruptedException(); } // 2.在doAcquireInterruptibly函数中,如果在执行完unpark之后,线程被中断,此时抛出异常。 if (!tryAcquire(arg)){ doAcquireInterruptibly(arg); } } |
(2)排他模式,与共享模式对应也有两个接口,如下:
- tryAcquireSharedNanos(int arg,long nanosTimeout),实现ReadLock的tryLock(time)接口。
- acquireSharedInterruptibly(int arg),实现ReadLock的lockInterruptibly接口。
1.3 同步器和具体同步器(如锁,信号量)的关系
AQS实现的功能:
- AQS定义了获取同步器和释放同步器的模板步骤,如下四个接口;
|
1 2 3 4 5 6 7 |
// 排它模式 acquire(int arg) release(int arg) // 共享模式 acquireShared(int arg), releaseShared(int arg) |
- AQS实现了在tryAcquire/tryAcquired抢占同步器失败之后操作
- AQS实现了在tryRelease和tryRelease抢占同步器成功之后的操作。
- AQS实现了Condition
但是AQS对于tryAcquired/tryAcquireShaed和tryRelease/tryReleaseShard操作,即具体抢占同步器和释放同步器的策略,留给具体同步器来做。所以,对于具体同步器 ,需要实现tryXXX的操作:
- 如果这个同步器采用排它模式,则需要实现tryAcquire(int arg)和 tryRelease(int arg)。 如Reentrantlock中FairSyn和NonfairSync两个具体的同步器。
- 如果这个同步器采用共享模式,则需要实现tryAcquireShared(int arg)和tryReleaseShared(int arg)两个方法。
总结,学习具体同步器时,如ReetrantLock,ReetrantReadWriteLock,关键看这些同步器实现tryAcquire/tryAcquired/tryRelease/tryRelease的逻辑。
1.4 如何表示一个线程获取了这个同步器
通过如下两个操作:
- 通过将同步器的当前线程的变量值设置为线程A,就表示这个线程A就是占有这个资源同步器。
- 再将此同步器的状态修改为已占用。
这样就可以理解同步器中“当前线程”和“状态”两个变量作用,除了这两个变量,同步器还需要一个FIFO对列,用于存储被阻塞的线程。解析当前线程、状态state,FIFO对列三个变量的含义:
- 当前线程:是为了保证锁的可重入性,如ReentLock实现的nonfairTryAcquire:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } // 判断是否为当前线程,实现可重入 else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } |
- state:就是标识该同步器是否已经被某个线程占用。
- FIFO对列:存放阻塞线程
2 常用数据结构
2.1 线程信息Node
FIFO队列的节点和Condition队列节点都是如下Node类:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Node { // 1.两种模式的常量值 static final Node SHARED = new Node(); static final Node EXCLUSIVE = null; // 2.节点状态 int waitStatus; // 四种状态常量 static final int CANCELLED = 1; static final int SIGNAL = -1; static final int CONDITION = -2; static final int PROPAGATE = -3; // 3.指针 Node prev; Node next; // 用于表示condition队列 和 同步队列的共享模式/互斥模式的两种模式 Node nextWaiter; // 4. 此线程节点对应的线程 Thread thread; } |
2.1.1 waitStatus 节点状态
1. waitStatus在Condition类中使用。
(1)当执行await操作时,新建的线程节点的状态为Node.CONDITION。
注意:对于acquire操作而言,新建的线程节点状态默认值为0。
(2)当执行single操作,此线程节点的状态值修改为0,然后将此节点从条件队列转移到同步队列中。
2.1.2 节点指针
1.为什么要有pre指针,即为什么要是双向队列。
应用:在release操作中执行unParksuccessor(Node),有时候需要从队尾部向前来找元素。
2. nextWaiter节点的作用
(1)在条件队列(Condition类中使用)中表示指向下一个节点的指针。
(2)在FIFO队列中表示线程节点的模式,包括排他和共享两种模式。
2.2 FIFO 队列
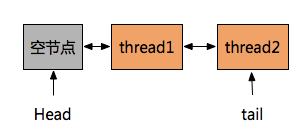
1、head节点是一个空
这个没有数据的节点(thread和prev的值都是null),如下两种方法生成head节点:
(1)可以通过调用默认构造函数来创建,如构造函数注释:
|
1 2 |
Node() { // Used to establish initial head or SHARED marker } |
(2)可以对线程节点进行如下设置
|
1 2 3 4 5 |
private void setHead(Node node) { head = node; node.thread = null; node.prev = null; } |
2、新增节点
新节点在队列末尾进行新增。
3 互斥模式
对外提供的public的接口有:
|
1 2 3 4 5 6 7 |
public final void acquire(int arg) public final void acquireInterruptibly(int arg) public final boolean tryAcquireNanos(int arg, long nanosTimeout) public final boolean release(int arg) |
3.1 acquire(int arg)
acquire的代码逻辑为:
|
1 2 3 4 5 6 7 8 9 10 11 |
public final void acquire(int arg) { // 1.第一步 通过tryAcquire获取同步器,如果没有获取同步器,就执行下一步 // 2.第二步 通过addWaiter来讲阻塞线程加入到FIFO队列 // 3.第三步 通过acquiredQueued来执行Lock#park阻塞线程 if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) // 4.第四步 执行中断 selfInterrupt(); } |
3.1.1 tryAcquire(arg)
在AQS是一个抽象方法,需要在具体的同步器重实现。可以参考ReentrantLock的FairSync和NonFairSync两个类中tryAccquire的实现:
- 可以获取到同步器,设置同步器状态和当前线程,返回true
- 没有获取到同步器,此时就返回false
3.1.2 addWaiter(Node mode)
1、作用
向FIFO队列末尾插入节点,可以指定节点模式如下:
- 对于排它模式:addWaiter(Node.EXCLUSIVE)。如ReetrantReadWriteLock#WriteLock和ReetrantLock通过这种方式创建节点。
- 共享模式节点:addWaiter(Node.SHARED)。对于ReetrantReadWriteLock#ReadLock通过这种方式创建节点
2、代码分析
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// 参数mode表示的是当前线程节点的模式是共享模式还是排它模式。 private Node addWaiter(Node mode) { Node node = new Node(Thread.currentThread(), mode); // Try the fast path of enq; backup to full enq on failure Node pred = tail; // 1. 如果对列不为空,则将新的节点插入到末尾 if (pred != null) { node.prev = pred; if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } // 2.如果对列为空,通过如下方法来初始化对列,并添加节点 enq(node); return node; } |
enq操作的代码如下,包括两步:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
private Node enq(final Node node) { for (;;) { Node t = tail; if (t == null) { // Must initialize // 1.第一步 初始化对列 if (compareAndSetHead(new Node())) tail = head; } else { // 2.第二步 将此新的节点插入到末尾 node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } |
3.1.3 acquireQueued(final Node node, int arg)
代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); //1.第一步 如果当前同步器可以获取,那么就执行线程,并重新设置head节点 // tryAcquire()作用:当我们通过release执行了unlock这个线程,那么此时需要tryAcquied来抢占同步器 if (p == head && tryAcquire(arg)) { // 1.1 移动Head指针,指向参数的node setHead(node); // 1.2 这里的p是原来的head指向的节点,为了回收这个节点这里next设置为null p.next = null; // help GC failed = false; return interrupted; } // 2 第二步 如果当前线程节点的前缀节点状态不是Node.SIGNAL,那么就设置为Node.SIGNAL //3 第三步 如果前缀节点状态为Node.SINGNAL,那么就执行park(); // 所以对于一个要被阻塞的线程节点,最多在这个for循环执行两次: // 第一次设置前缀节点状态为Node.SINGNAL, // 第二次执行parkAndCheckInterrupt来执行LockSupport#park if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } |
3.2 release(int arg)
1. 作用
(1)将同步器状态修改为未被占用和设置当前线程为Null
(2)当前线程head已经执行完成,触发执行head的下一个线程。获取FIFO队列的Head节点的下一个节点head->next,然后执行unpark操作,该head线程在acquireQueue函数中通过tryAcquired来继续进行抢占同步器,如果可以抢占到同步器,此时再重新设置同步器状态为已占用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public final boolean release(int arg) { // 1.释放同步器:修改同步器状态;修改同步器当前线程 if (tryRelease(arg)) { Node h = head; if (h != null && h.waitStatus != 0){ // 2.执行LockSupport#unpark() unparkSuccessor(h); } return true; } return false; } |
2、 理解unparkSuccessor
(1)作用
对于release和releaseShared两种模式,都是通过uparkSuceessor来释放同步队列上面的线程节点。
(2)当触发node的下一个节点开始执行,如果node的下一个节点不满足触发条件时,为什么是由末尾向首部移动的顺序来查找满足条件的节点?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
private void unparkSuccessor(Node node) { ...... Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; // 为什么是从末尾向前查找元素,而不是从前向后。 for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } .... } |
这是因为考虑到有的时候一个执行acquireNanos线程,此时等待的时间到了阈值,需要执行cacelAcquire操作,将这个节点从同步队列中移走。而此时有可能当前线程在执行release操作,正好head->next的值为需要取消任务的节点,此时unparkSuccesor从同步队列末尾向前找元素就避免了和caceleAcquire操作发生冲突。为了防止冲突,而逆向查找满足条件的节点,使cacelAcquire从同步队列中删除一个节点,没有带来任何影响。
3.3 tryAcquireNanos(int arg, long nanosTimeout)
和acquire的区别就是,当这个线程没有获取同步器被阻塞到FIFO队列之后,那么会等待一段时间,如果超过这个时间:
(1)再次执行tryAcquired来抢夺同步器
(2)如果没有抢夺上,通过 if (nanosTimeout <= 0)就返回false。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException { if (nanosTimeout <= 0L) return false; final long deadline = System.nanoTime() + nanosTimeout; final Node node = addWaiter(Node.EXCLUSIVE); boolean failed = true; try { for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return true; } nanosTimeout = deadline - System.nanoTime(); // 如果超出等待时间,就返回fase if (nanosTimeout <= 0L) return false; if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold) // 如果等待一个时间内,没有被执行unpark,则自动执行unpark LockSupport.parkNanos(this, nanosTimeout); if (Thread.interrupted()) throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } } |
当达到时间还是没有获取锁时,此时线程节点怎么处理?在执行 if(nanosTimout<=0)成功时,此时faled的值为为true,所以就会执行canelAcquire(node),即可以理解成:从同步队列中删除此线程节点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
private boolean doAcquireNanos(int arg, long nanosTimeout){ ..... boolean failed = true; try { for (;;) { ...... if (nanosTimeout <= 0) return false; ...... } } finally { // 在超过时间返回时,此时会执行如下函数 if (failed) cancelAcquire(node); } |
3.6 acquireInterruptibly(int arg)
和acquire的区别:就是为了响应线程的中断,即在得知线程是中断状态时抛出了一个异常,如下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
private void doAcquireInterruptibly(int arg) throws InterruptedException { final Node node = addWaiter(Node.EXCLUSIVE); boolean failed = true; try { for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) //如果发现线程中断,则抛出异常 throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } } |
4 共享模式
1. 与互斥模式区别
体现在acquireShared中的setHeadAndProgate的拓展性,即如果下一个节点是读节点就释放此线程节点。
2.对外提供的public的接口有:
|
1 2 3 4 5 6 7 |
public final void acquireShared(int arg) public final void acquireSharedInterruptibly(int arg) public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout) public final boolean releaseShared(int arg) |
1 和accquired代码的区别
区别:就在于这里定义了一个setHeadAndPropagate,代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
private void doAcquireShared(int arg) { //1.第一步 将线程节点添加到FIFO对列中 final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0) { //(1).重新设置Head. // (2)如果此时下一个节点为共享模式线程节点,则执行doReleaseShaed。 setHeadAndPropagate(node, r); p.next = null; // help GC if (interrupted) selfInterrupt(); failed = false; return; } } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } |
2 理解propagate的
(1)在共享模式下,通过setHeadAndProgate执行下一个共享节点时,直接执行doReleaseShared来释放此线程节点。(在互斥模式下都是通过release来释放线程节点的)
在setHeadAndPropagate中代码,如下:
|
1 2 3 4 5 6 7 |
if (propagate > 0 || h == null || h.waitStatus < 0) { Node s = node.next; if (s == null || s.isShared()){ // 不需要判断tryAcquireShared(),直接运行doReleaseShared doReleaseShared(); } } |
(2)举例
假设现在当前执行一个写线程,此时同步队列为:Head->读线程1->读线程2。那么当前写线程执行完之后,会通过release操作来执行读线程1,读线程1具有延展性,此时就会同时执行读线程2。这样就是说不是在读线程1执行完之后再执行读线程2,而是同时执行。
可以简单的理解doReleaseShared为:就是和release一样,释放Head->next的节点。为了提高效率,实现了release传递,这是release操作的区别了。举例如:假设线程A执行了dorelaseShard,触发了线程B,当线程B执行了acquireShard设置了head的位置,那么此时线程A的dorelaseShard就可以直接触发head下一个线程节点C,不需要再等待线程B执行doReleaseShard了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
private void doReleaseShared() { for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; // loop on failed CAS } // 循环中止条件 if (h == head) // loop if head changed break; } } |
4 利用AQS设计一个锁
1、设计一个锁需要两个步骤:
(1)第一步 自定义一个具体同步器(作为锁的内部类)
使用AbstractQueueSynchronizer自定义的同步器时,有两种模式可以采纳:
- 互斥模式。需要实现tryAcquire(int arg), tryRelease(int arg), isHeldExclusively()这三个方法
- 共享模式。需要实现tryAcquireShared(int arg),tryReleaseShared(int arg)这两个方法
(2)第二步 使用自定义的同步器来实现Lock接口
2、举例,可以参考如下代码 http://ifeve.com/introduce-abstractqueuedsynchronizer/
(1)第一步 自定义同步器
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
private static class Sync extends AbstractQueuedSynchronizer { // 是否处于占用状态 protected boolean isHeldExclusively() { return getState() == 1; } // 当状态为0的时候获取锁 public boolean tryAcquire(int acquires) { assert acquires == 1; // Otherwise unused if (compareAndSetState(0, 1)) { setExclusiveOwnerThread(Thread.currentThread()); return true; } return false; } // 释放锁,将状态设置为0 protected boolean tryRelease(int releases) { assert releases == 1; // Otherwise unused if (getState() == 0) throw new IllegalMonitorStateException(); setExclusiveOwnerThread(null); setState(0); return true; } // 返回一个Condition,每个condition都包含了一个condition队列 Condition newCondition() { return new ConditionObject(); } } |
(2)使用自定义的同步器来实现Lock
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Mutex implements Lock, java.io.Serializable { private final Sync sync = new Sync(); public void lock() { sync.acquire(1); } public boolean tryLock() { return sync.tryAcquire(1); } public void unlock() { sync.release(1); } public Condition newCondition() { return sync.newCondition(); } public boolean isLocked() { return sync.isHeldExclusively(); } public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); } public void lockInterruptibly() throws InterruptedException { sync.acquireInterruptibly(1); } public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException { return sync.tryAcquireNanos(1, unit.toNanos(timeout)); } } |
5 Unsafe#CompareAndSet
1. 解析作用
compareAndSet的作用,如支持并发的计数器,在进行计数的时候,首先读取当前的值,假设值为a,对当前值 + 1得到b,但是+1操作完以后,并不能直接修改原值为b,因为在进行+1操作的过程中,可能会有其它线程已经对原值进行了修改,所以在更新之前需要判断原值是不是等于a,如果不等于a,说明有其它线程修改了,需要重新读取原值进行操作,如果等于a,说明在+1的操作过程中,没有其它线程来修改值,我们就可以放心的更新原值了。
2、使用场景:
这里都是针对线程的共享变量来进行操作的。使用时,有点类似于乐观锁,首先获取一个原来值,然后执行更新操作,如果和原来值一样,就进行更新,如果不一样说明其他线程已经进行了更新,此时就返回错误。
3、使用举例
(1)跟原来值比较
int ws = p.waitStatus;
compareAndSetWaitStatus(p, ws, Node.SIGNAL)
(2)自己输入参数,如Node.CONDITION
compareAndSetWaitStatus(node, Node.CONDITION, 0)
4、如果更新失败怎么办
使用for来处理compareAndSetHead和compareAndSetTail的方法失败的情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
private Node enq(final Node node) { for (;;) { Node t = tail; if (t == null) { // Must initialize if (compareAndSetHead(new Node())) tail = head; } else { node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } } |
5、在同步器中应用
在同步器定义了如下compareAndSet方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
/** * CAS head field. Used only by enq. */ private final boolean compareAndSetHead(Node update) { return unsafe.compareAndSwapObject(this, headOffset, null, update); } /** * CAS tail field. Used only by enq. */ private final boolean compareAndSetTail(Node expect, Node update) { return unsafe.compareAndSwapObject(this, tailOffset, expect, update); } /** * CAS waitStatus field of a node. */ private static final boolean compareAndSetWaitStatus(Node node, int expect, int update) { return unsafe.compareAndSwapInt(node, waitStatusOffset, expect, update); } /** * CAS next field of a node. */ private static final boolean compareAndSetNext(Node node, Node expect, Node update) { return unsafe.compareAndSwapObject(node, nextOffset, expect, update); |
6 LockSupport
LockSupport是JDK中比较底层的类,用来创建锁和其他同步工具类的基本线程阻塞原语。java锁的核心AQS-AbstractQueuedSynchronizer,就是通过调用LockSupport.park()和LockSupport.unpark()实现线程的阻塞和唤醒的
6.1 函数
LockSupport提供了一个二元变量:0表示不可以执行。1表示可以执行。
1. LockSupport.park()
(1)如果此时二元变量为1,则可以执行线程。然后设置二元变量为0。
(2)如果此时二元变量为0,则一直阻塞。如下代码
|
1 2 3 4 |
public static void main(String[] args) { LockSupport.park(); System.out.println("block."); } |
由于默认情况下,可以看成这个二元变量为0,所以此时执行park()时,一直处于阻塞状态。
2. LockSupport.unpark()
(1)如果此时二元变量为0,则可以执行线程。然后设置二元变量为1。
(2)如果此时二元变量是1,那么不进行任务操作。
可以通过执行了两次unpark()来测试,第一次把二元变量从0修改为了1(默认情况下为0)。所以第二次就是在二元变量为1的情况下执行了。如下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public class LockSupportTest { public static void main(String[] args) throws Exception { final Thread thread1 = new Thread( new Runnable() { @Override public void run() { System.out.println("执行线程1--beg"); Thread thread = Thread.currentThread(); LockSupport.unpark(thread); LockSupport.unpark(thread); System.out.println("执行线程1--end"); } } ); thread1.start(); } } |
执行结果:
|
1 2 |
执行线程1--beg 执行线程1--end |
6.2 相关LockSupport总结
6.2.1 LockSupport是线程局部变量
LockSupport是线程的局部变量,不是线程间共享变量。
1、在线程2中调用unpark,但是参数是线程2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
public class LockSupportTest { public static void main(String[] args) throws Exception { Thread thread1 = new Thread( new Runnable() { @Override public void run() { System.out.println("执行线程1--beg"); System.out.println("park"); LockSupport.park(); System.out.println("执行线程1--end"); } } ); Thread thread2 = new Thread( new Runnable() { @Override public void run() { System.out.println("执行线程2--beg"); System.out.println("park"); Thread currentThread = Thread.currentThread(); LockSupport.unpark(currentThread); System.out.println("执行线程2--end"); } } ); thread1.start(); System.out.println("执行线程1之后休息1秒"); Thread.sleep(1000); thread2.start(); } } |
执行结果为,线程1处于阻塞状态,如下,没有打印“执行线程1–end”:
|
1 2 3 4 5 6 |
执行线程1之后休息1秒 执行线程1--beg park 执行线程2--beg park 执行线程2--end |
2、在线程2中调用unpark,参数修改为线程1
修改代码如下
|
1 2 3 4 5 6 7 8 9 10 |
Thread thread2 = new Thread( new Runnable() { @Override public void run() { System.out.println("执行线程2--beg"); LockSupport.unpark(thread1); System.out.println("执行线程2--end"); } } ); |
执行结果发现执行了线程1,:
|
1 2 3 4 5 6 |
执行线程1之后休息1秒 执行线程1--beg park 执行线程2--beg 执行线程2--end 执行线程1--end |
6.2.2 不可重入
执行了park操作之后,当前线程就会阻塞,不会像锁一样,同一个线程可以可重入的执行多次lock操作。如下代码
|
1 2 3 4 5 6 7 8 9 |
public class LockSupportTest { public static void main(String[] args) throws Exception{ Thread thread = Thread.currentThread(); System.out.println("a"); LockSupport.park(); System.out.println("b"); LockSupport.park(); } } |
执行结果:打印出a,但是不会打印出b。
6.2.3 支持相应中断
线程如果因为调用park而阻塞的话,能够响应中断请求(中断状态被设置成true),即会中断park(相当于执行了Unpark),但是不会抛出InterruptedException。代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public class LockSupportTest { public static void main(String[] args) throws Exception { final Thread thread1 = new Thread( new Runnable() { @Override public void run() { System.out.println("执行线程1--beg"); Thread thread = Thread.currentThread(); LockSupport.park(); System.out.println("执行线程1--end"); } } ); thread1.start(); thread1.interrupt(); } } |
执行结果分为两种情况:
- 如果不写thread1.interrupt,那么此时就会在LockSupport.park的位置阻塞住线程。
- 如果此时写了thread1.interrupt,那么此时线程就会打印出”执行线程1–end“。



