本文概览:介绍了在选型分布式系统时,我们期待的功能有哪些。xxl-job的功能概览。
1 问题背景
目前定时任务,只是在某一个固定机器上配置cron脚本。想引入一个分布式调度平台,对于这个平台我们亟需的功能呢?
1.1 期待的功能
我们经过比较目前开源分布式任务调度框架,选择了xxl-job,这个框架满足了我们所期待一个分布式任务调度平台的功能,而且还有一些意外的功能。
1、自动合理分配机器,避免在同一个时间点,任务都集中到同一个机器。 (✔️)
2、自动编排任务。 (✔️)
比如说task1….taskN,这个N个任务需要顺序执行,所以我们估算每个任务执行时长,去确定每个任务的执行时间点,但是某个任务因为处理数据变多或者其他因素时长变长,此时就会造成任务重叠。如果要解决这种重叠,又需要手动的配置各个任务执行时间点。
3、缺失任务运营
(1) 一共多少个任务 (✔️)
(2)一个时间点有多少任务运行(需要记录任务开始时间和结束时间) (✔️)
(3)当前正在运行哪些务 (✔️)
在出现线上问题时,迅速查看有哪些任务正在执行
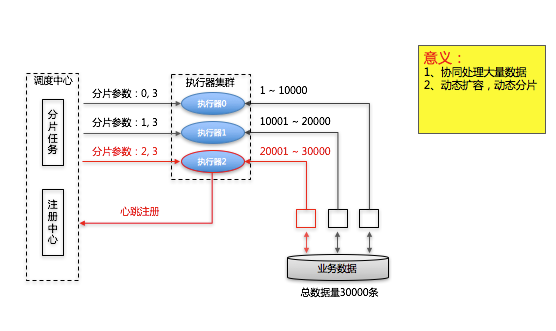
4、任务分片 (✔️)
考虑到个别任务文件量很大,执行慢。采用措施有:
- 文件划分成多个子文件
- 先解析文件入库,然后库数据进行划分(通过startIndex和endIndex来指定)。这里通过对数据库进行分片处理。因为 解析文件速度很快,而且文件还需要校验完整性,所以一般分批策略都是选择对数据库分片。
5、运行超时报警 (✔️)
运行超时会自动kill掉这个任务。
6、任务执行进度查看 (✔️)
通过在线日志打印进度
7、任务异常处理 (✔️)
- “故障转移”发生在调度阶段,在执行器集群部署时,如果某一台执行器发生故障,该策略支持自动进行Failover切换到一台正常的执行器机器并且完成调度请求流程。
- “失败重试”发生在”调度 + 执行”两个阶段,支持通过自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
除了上面我们能够想到功能,在查看xxl-job时还有额外的功能:
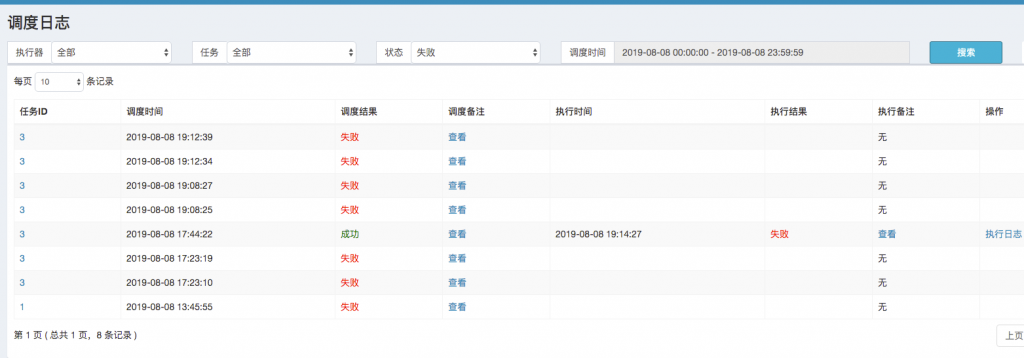
1、定时任务报错信息汇总 (✔️)
通过日期区间查询那些任务失败。可以查看当天有哪些失败的任务
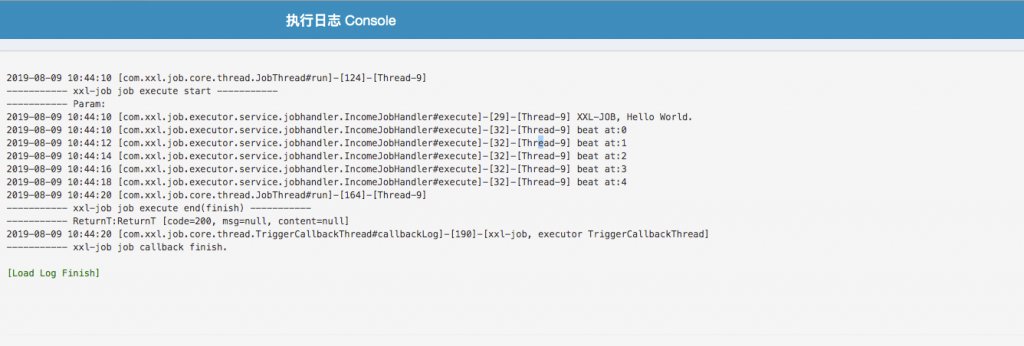
2、在线查看日志 ( ✔️)
可以用来打印执行进度。(打印总条数、打印已处理的个数来展示进度信息)
|
1 |
XxlJobLogger.log("beat at:" + i); |
1.2 XXL-JOB功能概览
如下是官网提供的所有功能:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
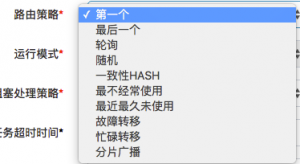
1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手; 2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效; 3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA; 4、执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA; 5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址; 6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务; 7、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等; 8、故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。 9、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度; 10、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务; 11、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试; 12、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式; 13、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务; 14、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。 15、事件触发:除了"Cron方式"和"任务依赖方式"触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。 16、任务进度监控:支持实时监控任务进度; 17、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志; 18、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。 19、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本; 20、命令行任务:原生提供通用命令行任务Handler(Bean任务,"CommandJobHandler");业务方只需要提供命令行即可; 21、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔; 22、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行; 23、自定义任务参数:支持在线配置调度任务入参,即时生效; 24、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞; 25、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性; 26、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件; 27、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用; 28、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等; 29、全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行; 30、跨平台:原生提供通用HTTP任务Handler(Bean任务,"HttpJobHandler");业务方只需要提供HTTP链接即可,不限制语言、平台; 31、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文; 32、容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用; 33、线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入"Slow"线程池,避免耗尽调度线程,提高系统稳定性; 34、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色; 35、权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作; |
2 xxl-job介绍
2.1 架构图
分为两大模块:调度中心 和 执行器服务。
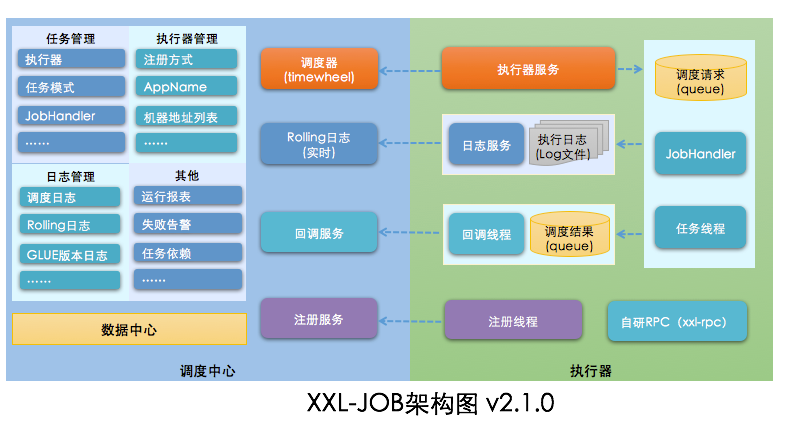
2.2 数据流程
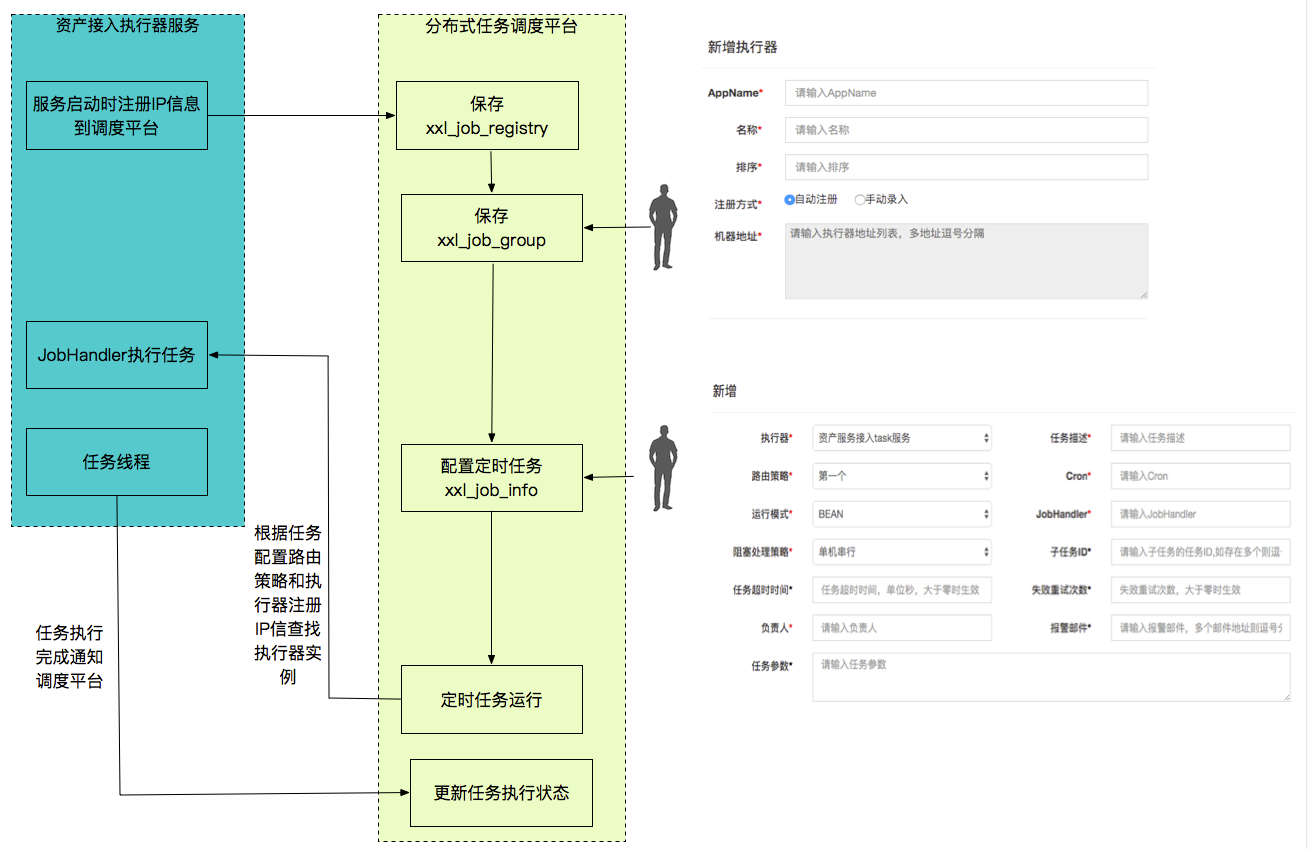
1、调度平台选择哪一个执行器?在配置任务时,通过这个调度策略来指定。
2.3 数据表含义
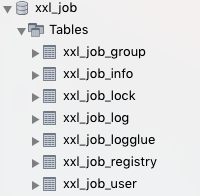
1、xxl_job_group。保存执行器服务的名称。
这个表信息需要手动新增的。字段说明:
- order。任务管理页面中下拉框的顺序。
|
1 2 3 4 5 6 7 8 9 |
Create Table: CREATE TABLE `xxl_job_group` ( `id` int(11) NOT NULL AUTO_INCREMENT, `app_name` varchar(64) NOT NULL COMMENT '执行器AppName', `title` varchar(12) NOT NULL COMMENT '执行器名称', `order` int(11) NOT NULL DEFAULT '0' COMMENT '排序', `address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入', `address_list` varchar(512) DEFAULT NULL COMMENT '执行器地址列表,多地址逗号分隔', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 |
对应如下信息

2、xxl_job_info。定时任务执行信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Create Table: CREATE TABLE `xxl_job_info` ( `id` int(11) NOT NULL AUTO_INCREMENT, `job_group` int(11) NOT NULL COMMENT '执行器主键ID', `job_cron` varchar(128) NOT NULL COMMENT '任务执行CRON', `job_desc` varchar(255) NOT NULL, `add_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `author` varchar(64) DEFAULT NULL COMMENT '作者', `alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件', `executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略', `executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler', `executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数', `executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略', `executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒', `executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数', `glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型', `glue_source` mediumtext COMMENT 'GLUE源代码', `glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注', `glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间', `child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔', `trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行', `trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间', `trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 |
3、xxl_job_registry。保存执行器服务的注册的IP信息,便于调度中心选择一个机器执行。
|
1 2 3 4 5 6 7 8 9 |
Create Table: CREATE TABLE `xxl_job_registry` ( `id` int(11) NOT NULL AUTO_INCREMENT, `registry_group` varchar(255) NOT NULL, `registry_key` varchar(255) NOT NULL, `registry_value` varchar(255) NOT NULL, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 |
如下:一个服务registry_key只能有一个记录,多个IP都追加到regitry_values
|
1 2 3 4 5 6 7 8 9 |
+----+----------------+-----------------------------+------------------+---------------------+ | id | registry_group | registry_key | registry_value | update_time | +----+----------------+-----------------------------+------------------+---------------------+ | 4 | EXECUTOR | assetaccess-excutor-service | 172.30.1.56:9999 | 2019-08-08 15:29:57 | +----+----------------+-----------------------------+------------------+---------------------+ |
4、xxl_job_logglue。任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
|
1 2 3 4 5 6 7 8 9 10 |
Create Table: CREATE TABLE `xxl_job_logglue` ( `id` int(11) NOT NULL AUTO_INCREMENT, `job_id` int(11) NOT NULL COMMENT '任务,主键ID', `glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型', `glue_source` mediumtext COMMENT 'GLUE源代码', `glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注', `add_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
3 XXL-job改造
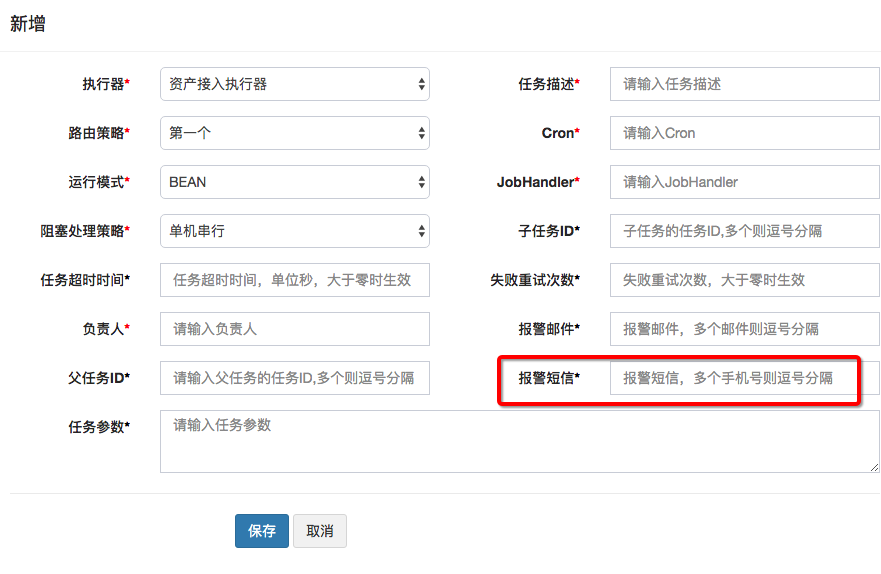
1、没有短信报警
在JobFailMonitorHelper.failAlarm代码中进行扩展。
2、没有任务依赖功能
目前只提供了一种功能,一个任务执行完成之后,自动触发它的子任务。但是却没有提供如下功能:如果一个任务需要依赖多个父任务,只有所有父任务执行完成之后,才能执行这个任务。
关于当前的依赖功能还有几点说明:
- 如果一个任务T配置了子任务ST,这个子任务ST也配置了cron自动触发,那么这个ST会在T执行完成之后触发一次,在cron时间点到达时候再触发一次
- 如果有多个任务T1,T2等都配置了子任务ST,则T1、T2等每个任务执行完成都会触发一次ST。
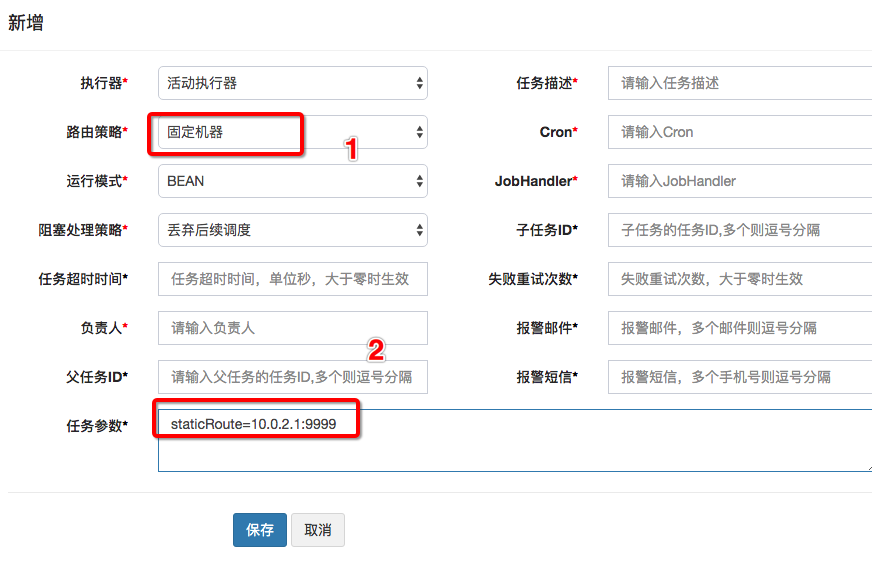
3、固定路由
指定执行器的IP机器,调度到指定的机器。最终实现如下:
- 路由策略选择:固定机器
- 任务参数新增:staticRoute=10.60.65.22:9999
4、任务重复调度问题
(1)数据库分为了主从两种方式,查询如下sql走了从库:
SELECT *
FROM xxl_job_info AS t
WHERE t.trigger_status = 1
and t.trigger_next_time< #{maxNextTime}
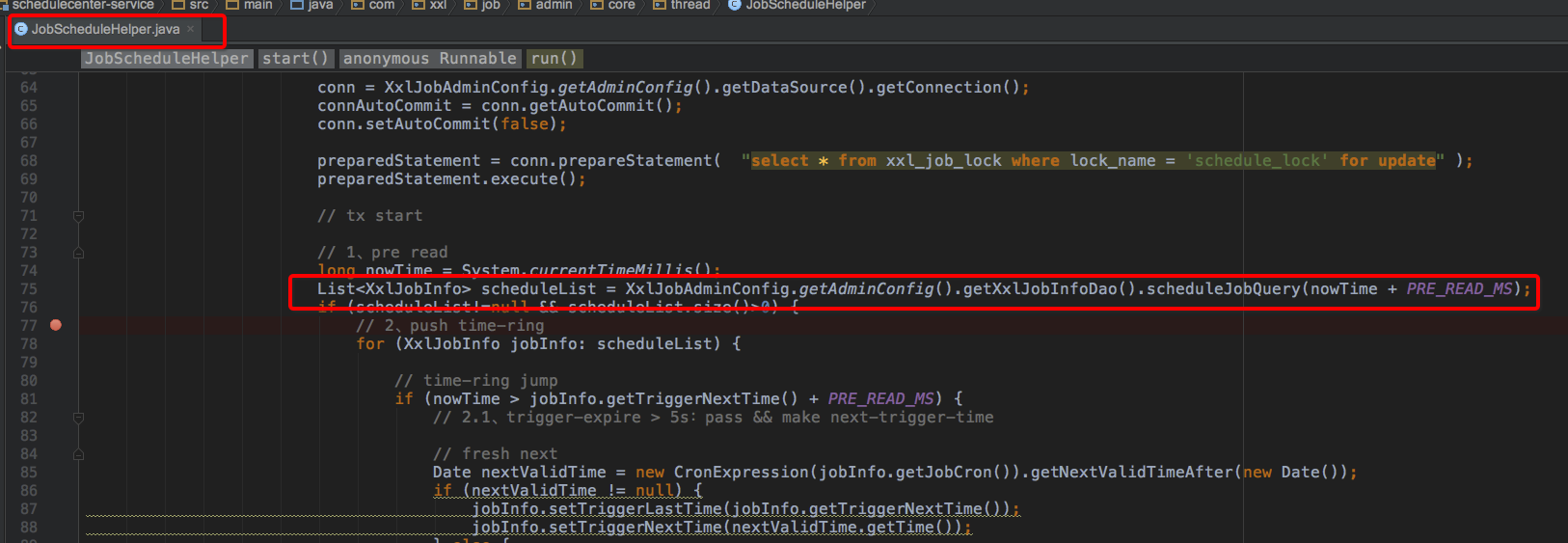
(2)问题解决
上面的查询走写库。
附:开源对比
参考:https://blog.csdn.net/guyue35/article/details/84883408
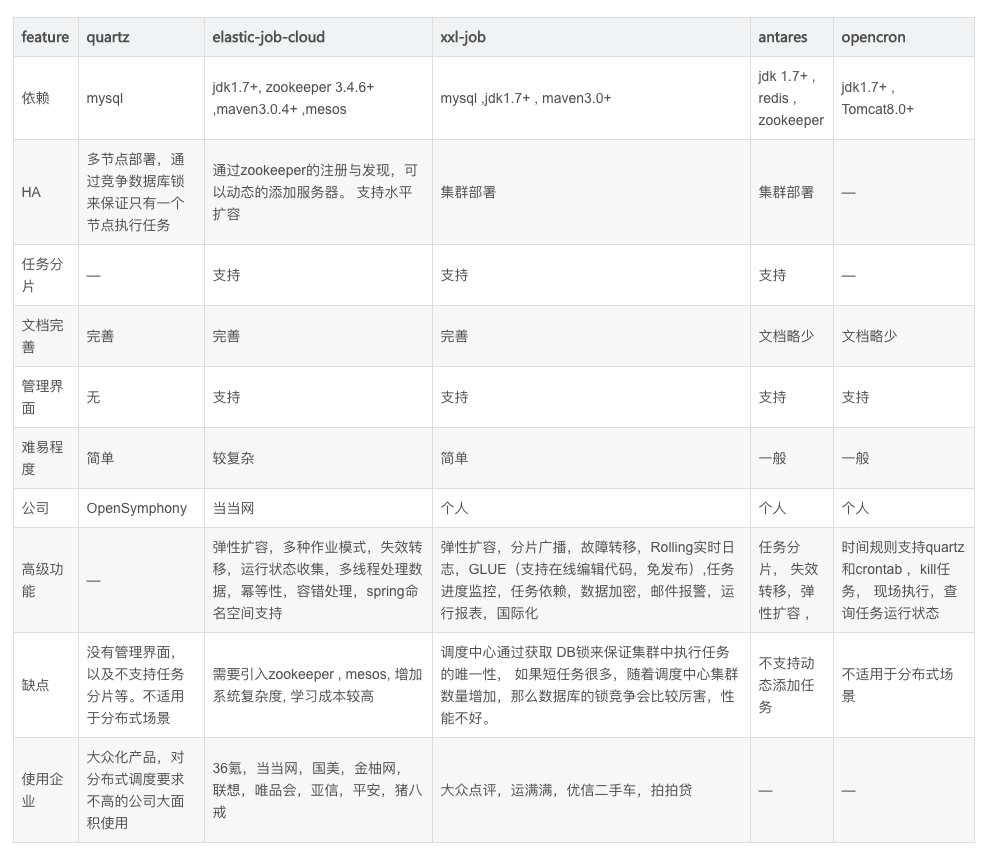
总结,选型xxl-job。原因:从功能上xxl-job和elastic-job差不多,考虑到如下:
- 使用xxl-job用户量大,有问题好解决。
- 容易扩展自定义功能,即易于二次开发。比如固定路由功能、短信报警等。
-
elastic-search是基于jar的。xxl-job是微服务。这个就涉及到了中间件是服务还是jar的对比了,当我们需要对调度中间件进行升级时,如果是jar,那么所有的引用jar的服务都需要做一次升级,成本较高。基于服务的中间件,只需要升级中间件服务就可以了。
-
xxl-job除了mysql,无外部依赖,可靠性高于elastic-search(依赖zookeeper)。
")



