本文概览:Sentinle dashboard运行一段时间服务服务hang住了,经过排查发现是因为GC时间多长导致。
1 问题描述
阿里的sentinle dashboard运行一时间之后,会出现服务hang住情况:服务进程还在在,但是调用服务无法成功。
2 问题分析
1、导出进程堆栈
|
1 |
jstack 进程ID > jstack.log |
2、top -H -p 服务进程
查看当前应用进程中占用cpu最多线程。比如线程Id为:25499
(2) 获取十六进制
|
1 |
printf %x 25499 |
(3)在jstack.log查看此十六进制。发现是JVM进程,怀疑是GC时间多长,导致cpu占用过高,整个应用hang死。
3、GC耗时导致
通过上面分析,初步确定是GC耗时太长,导致服务宕掉了。查看GC日志,GC的stop time都是1s+:
|
1 2 3 4 5 |
grep ' which application threads were stopped' gc.log.1.current | tail -n 30 2020-02-02T11:29:29.196+0800: 1015890.008: Total time for which application threads were stopped: 1.3696158 seconds, Stopping threads took: 0.0000462 seconds 2020-02-02T11:29:33.272+0800: 1015894.084: Total time for which application threads were stopped: 1.1266661 seconds, Stopping threads took: 0.0000412 seconds |
4、查看那些对象引起的gc,确认是否内存泄漏
logs下面有个perf文件,如果没有这个文件需要通过jmap命令来导出内存信息。通过mat分析
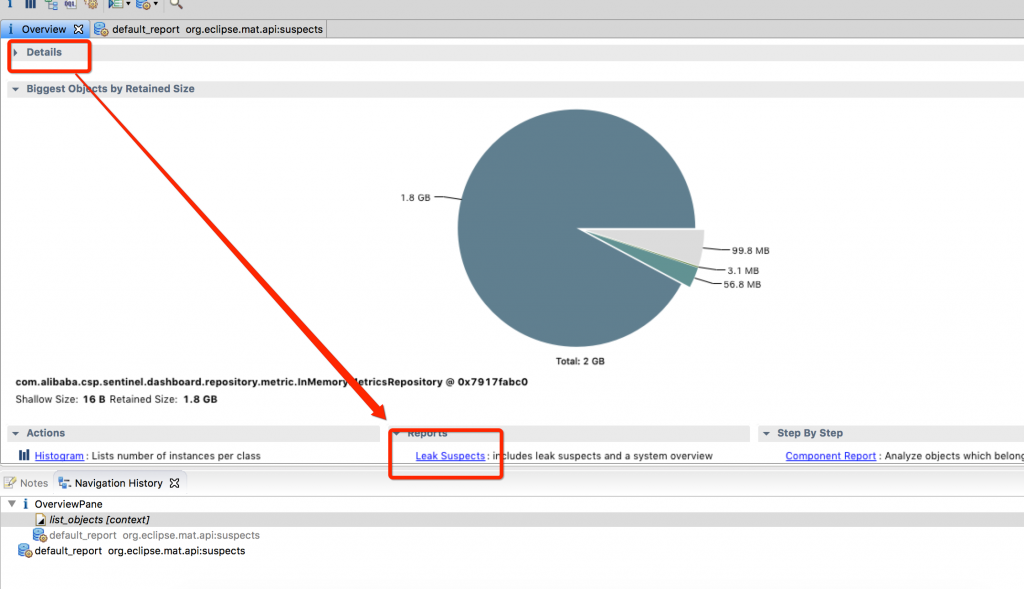
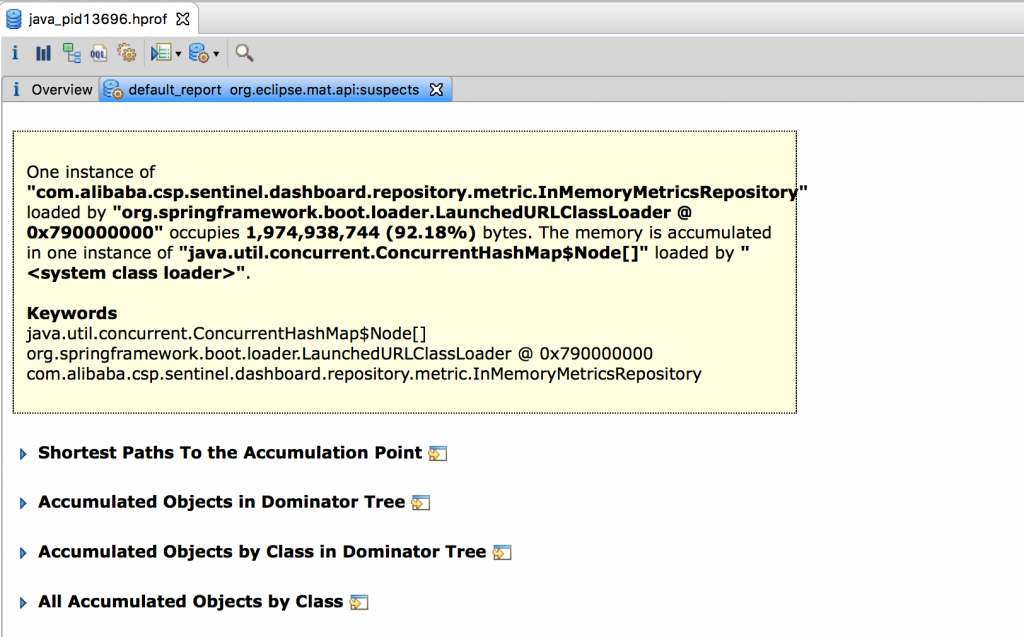
发现是由于InMemtricsRepository中这个成员中对象过多导致的。
|
1 2 3 4 5 6 7 |
public class InMemoryMetricsRepository implements MetricsRepository<MetricEntity> { /** * {@code app -> resource -> timestamp -> metric} */ private Map<String, Map<String, ConcurrentLinkedHashMap<Long, MetricEntity>>> allMetrics = new ConcurrentHashMap<>(); } |
5、解决方案
把指标数据都通过influxdb做持久化,不在使用InMemtricsRepository这个类。这样sentinel控制台页面中指标数据都可以通过influxdb来实现,不在放置在内存了。
附:JMAT使用相关问题
1、问题描述
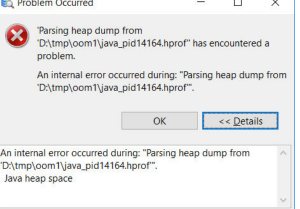
“jmat An internal error occurred during: “Parsing heap dump from'”. Java heap space”,如下图
2、解决
参考:https://better-coding.com/solved-eclipse-mat-java-heap-space-error/
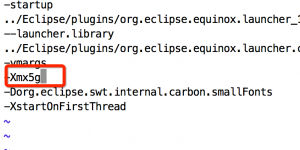
在/Applications/mat.app/Contents/Eclipse 设置 MemoryAnalyzer.ini,设置-Xmx参数为5g。
因为我们的perf日志文件是4G,所以设置为5G
2、解决
参考:https://better-coding.com/solved-eclipse-mat-java-heap-space-error/
在/Applications/mat.app/Contents/Eclipse 设置 MemoryAnalyzer.ini,设置-Xmx参数为5g。
因为我们的perf日志文件是4G,所以设置为5G
")



")
")