本文总结:
- 回收内存机制有哪些?主要包括包括两个:
- 清理达到过期时间时间的键
- maxmemory设置的内存上限,触发回收策略。
1 淘汰策略
回收内存机制主要包括包括两个:
- 清理达到过期时间时间的键
- maxmemory设置的内存上限,触发回收策略
1.1 清理过期时间的键
主要包括惰性删除和定期两种方式:
惰性删除:每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
定期删除:每隔一段时间(每秒运行10次),程序就对数据库进行一次检查,删除里面的过期键。
1.2 达到内存上限触发回收
内存使用达到maxmemory设置的内存上限时,触发内存溢出策略(maxmemory-policy参数)。默认策略是volatile-lru:
- noeviction:不删除任何键,只响应读操作,拒绝写入操作。如果有写入操作返回错误”OOM command not allowed when used memory”。
- allkeys-lru: 根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-lfu: 根据LFU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random: 随机删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- volatile-lru: 根据LRU算法删除设置了过期时间(expire)的键,直到腾出足够空间为止。
- volatile-random: 随机删除设置了过期时间(expire)的键,直到腾出足够空间为止。
- volatile-lfu: 根据LFU算法删除设置了过期时间(expire)的键,直到腾出足够空间为止。
- volatile-ttl: 删除最近将要过期数据,直到腾出足够空间为止。TTL, time to live,剩余存活时间。通过 “TTL key xx”进行设置。
说明:
- volatile-xx策略,是针对设置过期时间的键。只会删除设置了过期时间的键,对于没有设置过期时间的键会一致保存。
- LRU和LFU。LRU(Least Recently Used)最近最少使用,是按照使用时间排序的,过滤很久之前访问的数据;LFU(Least Frequently Used)最近最不常用,是按照访问次数进行过滤的,顾虑频率最低的数据。
2.3 LRU改进
算法元素:
- Redis 默认会记录每个数据的最近一次访问的时间戳(RedisObject 中的 lru 字段)
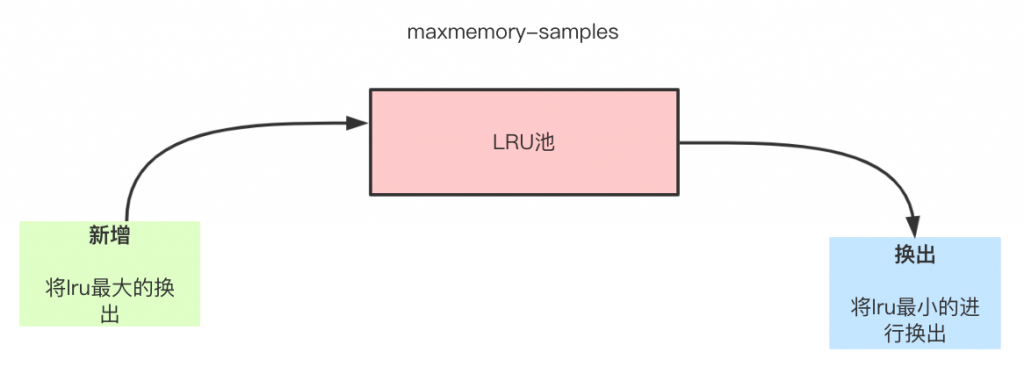
- maxmemory_samples: 随机采样的精度,也就是随即取出key的数目。该数值配置越大, 越接近于真实的LRU算法,但是数值越大,相应消耗也变高,对性能有一定影响,样本值默认为5;这个配置为10时已经非常接近全量LRU的精准度了。
策略:
- 初始化:Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据( maxmemory-samples),把它们作为一个候选集合。
- 新增样本:将lru较大从lru池中剔除。
- 淘汰策略:把lru池中 lru 最小的数据从缓存中淘汰出去。
2 基于LinkedHashMap实现LRU
2.1 LinkedHashMap结构
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持插入和访问两种顺序。
- 插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
- 访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
默认都采用插入顺序来维持取出键值对的次序,如果使用如下构造方法将accessOrder设置为true。
|
1 2 3 4 5 6 |
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; } |
和Hashmap结构区别:LinkedHashMap 相比 HashMap 的拉链式存储结构,内部额外通过 Entry 维护了一个双向链表,Entry多了一个before和after指针。
|
1 2 3 4 5 6 7 8 |
private static class Entry<K,V> extends HashMap.Entry<K,V> { // These fields comprise the doubly linked list used for iteration. Entry<K,V> before, after; Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } } |
2.2 实现LRU
源码中add操作会用到removeEldestEntry,
|
1 2 3 4 5 6 7 8 9 |
void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex); // Remove eldest entry if instructed Entry<K,V> eldest = header.after; if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } } |
默认removeEldestEntry直接返回false,只需要复写removeEldestEntry方法即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class LruMap<K,V> extends LinkedHashMap<K, V> { private int maxSize; public LruMap(int initialCapacity, float loadFactor, boolean accessOrder, int maxSize) { super(initialCapacity, loadFactor, accessOrder); this.maxSize = maxSize; } public LruMap(int maxSize) { this(16, 0.75f, true, maxSize); } public LruMap(int tableSize, int maxSize) { this(tableSize, 0.75f, true, maxSize); } @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { boolean flag = size() > maxSize; if (flag) { System.out.println("移除头节点, key:" + eldest.getKey() + ", value:" + eldest.getValue()); } return flag; } } |