本文概览:介绍了influxDb部署、influxDb的表结构、influxDb的两种操作方式以及influxDb数据展示。
1 InfluxDb介绍
Influx面向的是实时数据,即时间序列。查看维基内容如下:
“InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。”
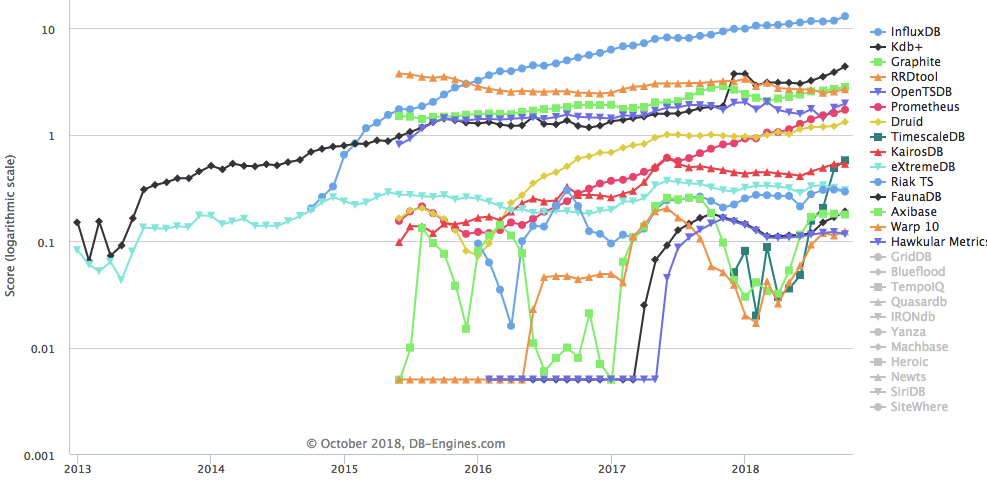
目前比较流行的时间序列数据库TSDB,如下图:https://db-engines.com/en/ranking_trend/time+series+dbms
2 部署InfluxDb
https://docs.influxdata.com/influxdb/v0.10/introduction/installation/
2.1 Mac下部署
1、安装
通过如下命令进行安装:
|
1 2 |
brew update brew install influxdb |
2、启动和关闭服务
启动服务
|
1 |
brew services start influxdb |
关闭服务
|
1 |
brew services stop influxdb |
3、通过lsof来查看启动服务和端口,如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
HeartThinkDo@B000000064800:~$ lsof -nP | grep influxd influxd 22199 HeartThinkDo txt REG 1,4 32768 54368139 /private/var/db/mds/messages/se_SecurityMessages influxd 22199 HeartThinkDo txt REG 1,4 26287392 412850 /usr/share/icu/icudt55l.dat influxd 22199 HeartThinkDo txt REG 1,4 639664 407379 /usr/lib/dyld influxd 22199 HeartThinkDo txt REG 1,4 558288206 25685661 /private/var/db/dyld/dyld_shared_cache_x86_64h influxd 22199 HeartThinkDo 0r CHR 3,2 0t0 302 /dev/null influxd 22199 HeartThinkDo 1u REG 1,4 14039 58884153 /usr/local/var/log/influxdb.log influxd 22199 HeartThinkDo 2u REG 1,4 14039 58884153 /usr/local/var/log/influxdb.log influxd 22199 HeartThinkDo 3u IPv4 0x172e9ccc4d52bf09 0t0 TCP 127.0.0.1:8088 (LISTEN) influxd 22199 HeartThinkDo 4u KQUEUE count=0, state=0xa influxd 22199 HeartThinkDo 5u REG 1,4 164101 58885744 /usr/local/var/influxdb/wal/_internal/monitor/1/_00003.wal influxd 22199 HeartThinkDo 6u IPv6 0x172e9ccc40eafef1 0t0 TCP *:8086 (LISTEN) ...... |
4、通过两种方式登录
(1)终端
启动服务之后,在终端输入“influx”命令,如下
|
1 2 3 4 |
HeartThinkDo@B000000064800:~$ influx Connected to http://localhost:8086 version v1.3.5 InfluxDB shell version: v1.3.5 > |
(2)还可以通过web页面 http://localhost:8083。但是无法访问,查看官网解释:
Versions 1.3+ of InfluxDB and InfluxEnterprise no longer support the web admin interface, the builtin user interface for writing and querying data in InfluxDB. Chronograf replaces the web admin interface with improved tooling for querying data, writing data, and database management.
2.2 CentOS
2.2.1 方式1 通过rpm包安装
1、部署如下,参考 https://portal.influxdata.com/downloads
|
1 2 3 |
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.3.7.x86_64.rpm sudo yum localinstall influxdb-1.3.7.x86_64.rpm |
注意:上面的wget无法下载时,可以手动的从https://repos.influxdata.com/rhel/7/x86_64/stable/ 下载influxdb-1.3.7.x86_64.rpm。
2、启动
|
1 |
service influxdb start |
2.2.2 方式2 通过tar包进行 (推荐)
参考 https://portal.influxdata.com/downloads
|
1 2 3 |
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.3.7-static_linux_amd64.tar.gz tar xvfz influxdb-1.3.7-static_linux_amd64.tar.gz |
执行启动。在解压包的influxdb-1.3.7-1/usr/bin的下面找到influxd,启动如下
|
1 |
nohup ./influxd >/dev/null 2>&1 & |
中止服务
|
1 |
kill -9 进程id |
3 配置文件
参考官网:https://docs.influxdata.com/influxdb/v1.6/administration/config/
1、配置文件的路径
安装方式为:选择Centos下通过tar包进行(服务器线上选择这种模式)。
对应配置文件目录:解压目录/influxdb-1.3.7-1/etc/influxdb/influxdb.conf
2、配置保存数据路径
|
1 2 3 |
dir = "/home/influx/data/influxdb/meta" dir = "/home/influx/data/influxdb/data" wal-dir = "/home/influx/data/influxdb/wal" |
3、重启服务
修改配置文件之后,还需要通过“-config”来指定配置问阿金,否则就不会生效。这是因为默认情况下influx会使用默认的配置,必须显示指定配置文件路径,才能生效配置。
|
1 |
./influxd -config /home/influx/local/influxdb-1.3.7-1/etc/influxdb/influxdb.conf |
4、在没有显示指定配置文件时,我们想看下默认配置文件的属性,可以在安装目录的influxdb-1.3.7-1/usr/bin目录下通过如下命令进行查看,
|
1 |
./influxd config |
5、查看数据占用磁盘大小
查看上面配置文件中指定的数据目录“/home//influx/data/influxdb ”的大小
4 influxDb基本概念
4.1 概念解析
1、表结构
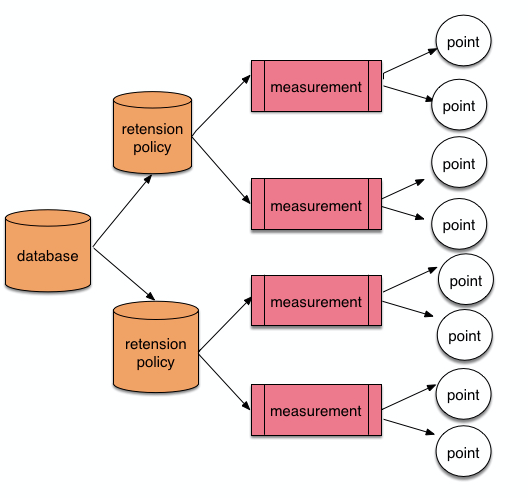
(1)database,和mysql一样,表示数据库。
(2)measurement,类似SQL数据表。和mysql数据表不同的是,不再需要我们自己建立数据表,在我们插入一个Point时,可以理解为根据measurement建立一个数据表。
(3)ponint,相当于一行数据,point可以理解为一个 时间点 的数据,因为influxDb是基于时间序列的。
|
1 |
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp] |
包括四个部分:
- measurement,相当于mysql数据库表名【必填项】。
- tag-key,可以0~多个【选填项】。tag-value的类型必须都是String类型。
- field-key,保存我们需要统计数据。1~多个【必填项】。field-value的类型可以是strings、floats、 integers 或者 booleans。
- timestapmp,时间戳,是主键,默认当前时间 【选填项】
2、比较tag和field
(1)先说下feild
在一个二维坐标系中,如果我们绘制一个曲线,需要一系列的点”(x=x1,y=y1),…,(x=xn,y=yn)”。在influxDb中,可以把x坐标轴理解为timestamp字段的值,凸显了时间序列的概念。为什么可以多个<field-key,field-value>?这是因为可能在一个坐标系中可能需要绘制多条线。
(2)再说下tag
tag作用就是为了作为索引来实现快速的查询fied的数据。在influxDb中对于field是没有索引的,如果根据field查询数据时需要扫描数据,而tag是有索引的,根据tag作为查询条件查询field时,速度会很快。
3、retention policy
备份数据的策略,主要包括数据保留时间和备份个数两个信息。查询licai-data数据库上面的retension policy,如下
|
1 2 3 4 5 |
> SHOW RETENTION POLICIES ON "licaidata" name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 168h0m0s 1 false rp_licaidata 480h0m0s 24h0m0s 1 true |
4、serires
它是由database、retension policy确定的一个measurement中所有tag的组合。查看series
|
1 2 3 4 5 6 |
> show series from cpu key --- cpu,host=serverA,region=us_earth cpu,host=serverA,region=us_east cpu,host=serverA,region=us_west |
5、关于唯一键
如何表示唯一Pont?可以由series和timestamp来唯一标识,或者说由database、retension policy、measurement、tagsets、timestamp来唯一标识,因为series是由database、retension policy确定的一个measurement中所有tag的组合,所以等同于database、retension policy、measurement和tagsets。
对于一个database有多个retension policy,对于每一个retenison policy都是表的集合。所以当我们查询一个表时,必须指定这个表所在的retension pliciy
|
1 |
select * from cpu #如果不指定就取默认 |
上面写法等于
|
1 |
select * from rp_licaidat.cpu; # rp_licaidat是licaidata指定默认的retension policiy |
当database和retension policy固定之后,对于一个measurement,如果存在timestamp相同的多条记录,分为如下两种情况:
(1)情况1:如果serrites相同,则此时只会保存一条Point记录,Point中field-value更新为最新的值 。如下
|
1 2 3 4 5 |
# 第一个 INSERT cpu,host=serverA,region=us_west value=0.98 1504801818220668688 # 第二个 INSERT cpu,host=serverA,region=us_west value=0.28 1504801818220668688 |
查询如下:
|
1 2 3 4 5 |
> select * from cpu where host='serverA' name: cpu time host region value ---- ---- ------ ----- 1504801818220668688 serverA us_west 0.28 |
(2)情况2:,如果serrrites不同,则会有多条Point记录。如下
|
1 2 3 4 5 |
# 第一个 INSERT cpu,host=serverA,region=us_west value=0.28 1504801818220668688 # 第二个 INSERT cpu,host=serverA,region=us_earth value=0.28 1504801818220668688 |
查看如下:
|
1 2 3 4 5 6 |
> select * from cpu where host='serverA' name: cpu time host region value ---- ---- ------ ----- 1504801818220668688 serverA us_earth 0.28 1504801818220668688 serverA us_west 0.28 |
5 终端方式
提供了类似于SQL的查询命令,本节进行介绍。
5.1 连接
直接通过influx登录,也可以通过如下命令进行远程登录
|
1 |
influx -host xx.xx.xx.xx -port 8086 |
5.2 数据库操作
1、创建数据库
|
1 |
> create database licaidata |
2、查看数据库
|
1 2 3 4 5 6 |
> show databases; name: databases name ---- _internal licaidata |
3、切换到当前数据库
|
1 2 |
> use licaidata Using database licaidata |
5.3 数据表操作
1、查看所有表
|
1 2 3 4 5 |
> show measurements; name: measurements name ---- monitor |
1、增
当measument相同时,如果插入多条时间搓一样的记录,则只会保留最新的值。
|
1 |
INSERT cpu,host=serverA,region=us_west value=0.98 |
2、查询记录
(1)查询一个表中所有数据
|
1 2 3 4 5 |
> select * from cpu; name: cpu time host region value ---- ---- ------ ----- 1504881808785291991 serverA us_west 0.98 |
(2)查看数据库中所有记录,通过”/.*/”表示所有的表
|
1 |
select * from /.*/; |
(3)根据tag-key查询【推荐】
查询数据时,都是按照tag-key进行查询,因为tag-key是存在索引的。
|
1 |
select * from cpu where host='serverA' |
(4)根据field-key进行查询
|
1 2 3 4 5 |
> select * from cpu where value=0.98 name: cpu time host region value ---- ---- ------ ----- 1505139978815880541 serverA us_west 0.98 |
3、删除和更新记录
influxDb没有提供删除和更新操作,都是通过“Retention Policies”来进行配置
4、删除表
|
1 |
DROP MEASUREMENT <measurement_name> |
5、limit操作
|
1 |
limit pageSize offset startIndx |
如limit 10 offset 0,从第一个元素取10个,
limit 10 offset 1,从第二个元素开始取10个。
5.4 Retention Policy
5.4.1 概念解释
备份数据的策略,主要包括数据保留时间和备份个数两个信息。官网中retention policy的两个作用
“A retention policy describes how long InfluxDB keeps data (DURATION) and how many copies of those data are stored in the cluster (REPLICATION)”
但是,备份个数只针对于集群机器,对于单点模式不起作用,需要设置为1。
Replication factors do not serve a purpose with single node instances.
1、Shard和ShardGroup
(1)ShardGroup
influxdb假设保留1个月数据,ShardGroup作用就是按某一个时间间隔来归档这些数据,比如按日归档,就是1号数据是一个ShardGroup1,2号数据是ShardGroup2。
(2)Shard
Shard是真正存储数据的。对于ShardGroup还需要按照series来划分,每一个Shard负责存储一些Series的信息,比如ShardGroup1下面有个Shard1,负责存储seriesA和seriesB的数据,那么此时Shard1里面数据就是seriesA和seriesB在1号的数据。
2、ShardGroup是如何设置时间区间的
默认情况下都是由保存策略来设置的。存在如下对应关系
| RP Duration | Shard Group Duration |
| <2days | 1 hour |
|
>=2days and <= 6 months |
1 day |
|
>6 months |
7 days |
5.4.2 基本操作
1、新增
Retention 是基于数据库的。如果没有自定义,那么都有一个默认的值,如下
|
1 2 3 4 |
> SHOW RETENTION POLICIES ON "licaidata" name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 168h0m0s 1 true |
如果想要新增一个,可以通过如下命令模式进行新增一个retention策略,如下
|
1 |
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [DEFAULT] |
(1)retention_policy_name,表示策略名称
(2)datbase_name,表示数据库名称。 retention策略是基于数据库的。此属性为必填项,所以Retention policy只针对某一个数据库进行创建的,不支持对全量的配置(对所有数据库都生效)。
(3) duration,表示的是时间长度。
- m表示分钟
- h表示小时
- d表示天数
- w表示周
(4) n,表示的是备份的份数。
(5) DEFAULT,用来把当前策略设置为默认策略
举例如下,保存20天数据和备份1份
|
1 |
CREATE RETENTION POLICY "rp_licaidata" ON "licaidata" DURATION 20d REPLICATION 1 DEFAULT |
2、 查询
查询licai-data数据库上面的retension policy
|
1 2 3 4 5 |
> SHOW RETENTION POLICIES ON "licaidata" name duration shardGroupDuration replicaN default ---- -------- ------------------ -------- ------- autogen 0s 168h0m0s 1 false rp_licaidata 480h0m0s 24h0m0s 1 true |
3、修改
|
1 |
ALTER RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [DEFAULT] |
对于上面新建的rp_licaidata策略执行如下更新操作
(1)只更新保存时间
|
1 |
alter retention policy rp_licaidat on licaidata duration 30d |
(2)只更新是否为默认策略
|
1 |
alter retention policy rp_licaidat on licaidata DEFAULT |
4、删除
DROP RETENTION POLICY <retention_policy_name> ON <database_name>
- retention_policy_name,表示策略名称
- datbase_name,表示数据库名称。 retention策略是基于数据库的。
5.5 series相关操作
1、查看series
|
1 2 3 4 5 6 |
> show series from cpu key --- cpu,host=serverA,region=us_earth cpu,host=serverA,region=us_east cpu,host=serverA,region=us_west |
2、删除series的命令格式为
|
1 |
DROP SERIES FROM <measurement_name[,measurement_name]> WHERE <tag_key>='<tag_value>' |
3、快速查看一个tag值,比如ip是一个tag
|
1 |
SHOW TAG VALUES FROM "http_server_requests" WITH KEY = "ip" |
6 接口方式
6.1 数据库操作
创建数据库
|
1 |
curl -G http://localhost:8086/query --data-urlencode "q=CREATE DATABASE licaidata" |
6.2 查询
1、单个sql查询
查询语句如下:
|
1 |
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=licaidata" --data-urlencode "q=SELECT value FROM cpu WHERE region='us_west'" |
其中
- db=licaidata,是设置数据库为licaidata
- q=xxx,是设置查询语句(就是通过终端查询的语句)
查询结果为
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "results": [ { "statement_id": 0, "series": [ { "name": "cpu", "columns": [ "time", "value" ], "values": [ [ "2017-09-11T14:26:18.815880541Z", 0.98 ], [ "2017-09-11T14:32:35.002717848Z", 0.89 ], [ "2017-09-11T14:33:23.240842149Z", 0.79 ] ] } ] } ] } |
上面的time都是yyyy-mm-dd的显示,如果我们要显示时间搓,则使用 epoch=ms,如下
|
1 |
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=licaidata" --data-urlencode "q=SELECT value FROM cpu WHERE region='us_west'&epoch=ms" |
2、多个sql查询
相对于单个sql区别,就是通过”q=sql;sql2“在q后面添加多个sql,多个sql用分号隔开,如下
|
1 |
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=licaidata" --data-urlencode "q=SELECT value FROM cpu WHERE region='us_east';SELECT count(value) FROM cpu WHERE region='us_east'" |
查询结果为
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
{ "results": [ { "statement_id": 0, "series": [ { "name": "cpu", "columns": [ "time", "value" ], "values": [ [ "2017-09-11T14:33:01.287569226Z", 0.89 ], [ "2017-09-11T14:33:14.22443498Z", 0.76 ] ] } ] }, { "statement_id": 1, "series": [ { "name": "cpu", "columns": [ "time", "count" ], "values": [ [ "1970-01-01T00:00:00Z", 2 ] ] } ] } ] } |
5.3 新增
1、插入一条数据
|
1 |
curl -i -XPOST 'http://localhost:8086/write?db=licaidata' --data-binary 'cpu,host=serverA,region=us_west value=0.69' |
- write表示是写操作
- db=licaidata,表示数据库
- 最后后面字符串是sql中insert语句后面字符串
执行结果为
|
1 2 3 4 5 |
HTTP/1.1 204 No Content Content-Type: application/json Request-Id: 84dee35d-9702-11e7-80e5-000000000000 X-Influxdb-Version: v1.3.5 Date: Mon, 11 Sep 2017 15:04:33 GMT |
2、插入多条数据
插入多条数据时数据之间必须是分行,如下插入了三条数据,每条数据必须占一行
|
1 2 3 |
curl -i -XPOST 'http://localhost:8086/write?db=licaidata' --data-binary 'cpu,host=serverA,region=us_west value=0.60 cpu,host=serverA,region=us_west value=0.59 cpu,host=serverA,region=us_west value=0.39' |
执行结果如下:
|
1 2 3 4 5 |
HTTP/1.1 204 No Content Content-Type: application/json Request-Id: 48d26131-9703-11e7-80ed-000000000000 X-Influxdb-Version: v1.3.5 Date: Mon, 11 Sep 2017 15:10:02 GMT |
7 influxData 函数
聚集函数操作对象时field数据,不是tag数据。官方wiki: https://docs.influxdata.com/influxdb/v1.3/query_language/functions
7.1 聚合
1、mean
- 功能:计算平均值
- 实例:
|
1 2 3 4 5 |
> SELECT mean(value) FROM cpu name: cpu time mean ---- ---- 0 0.75222 |
7.2 选择器
1、max
- 功能:选择最大
- 实例:
|
1 2 3 4 5 |
> SELECT max(value) FROM cpu name: cpu time max ---- --- 1505139978815880541 0.98 |
8 使用Chronograf展示数据
8.1 部署
安装Chronograf来代替之前的admin页面
1、通过如下命令按照
|
1 2 |
brew update brew install chronograf |
或者通过 https://portal.influxdata.com/downloads 进行下载
2、启动和关闭服务
|
1 2 3 4 5 |
# 启动服务 brew services start chronograf # 关闭服务 brew services stop chronograf |
3、查看服务
|
1 2 3 4 |
HeartThinkDo@B000000064800:$ lsof -nP | grep chronogra ....... chronogra 22978 wuzhonghu 5u IPv6 0x172e9ccc45971ed1 0t0 TCP *:8888 (LISTEN) ........ |
4、输入:http://localhost:8888/。用户和密码都是admin。
8.2 查询和写入数据
8.2.1 查询数据
1、选择数据源,并进行连接
2、选择查询条件,并展示结果,分为:Graph和Table两种展示。
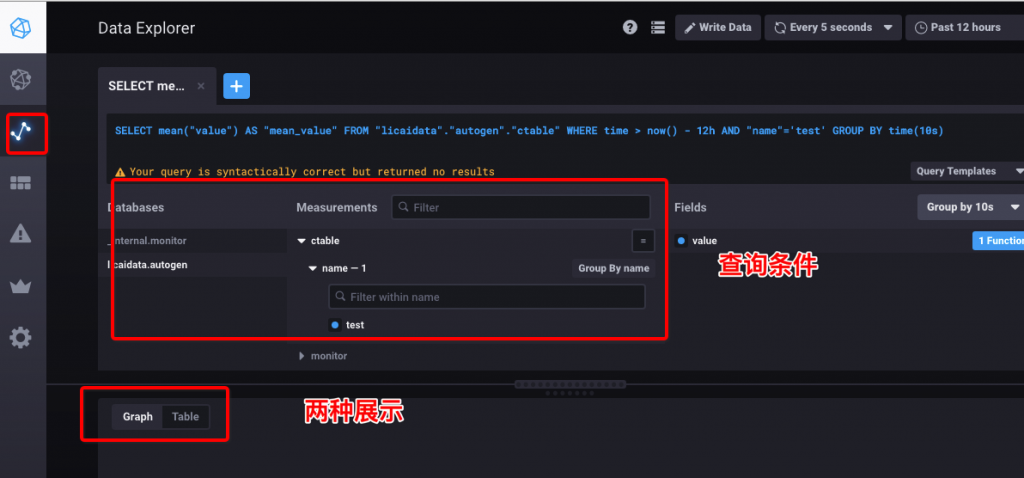
8.2.2 写入数据
1、选择“write data”
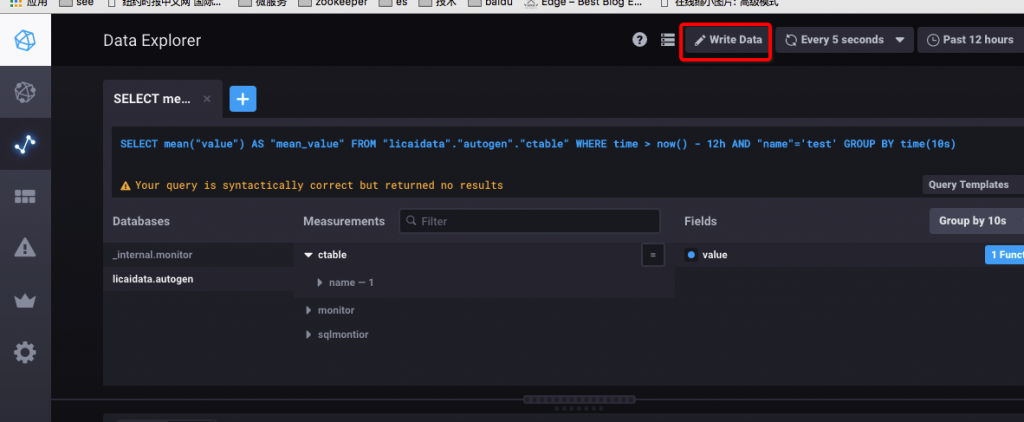
2、选择直接输入命令
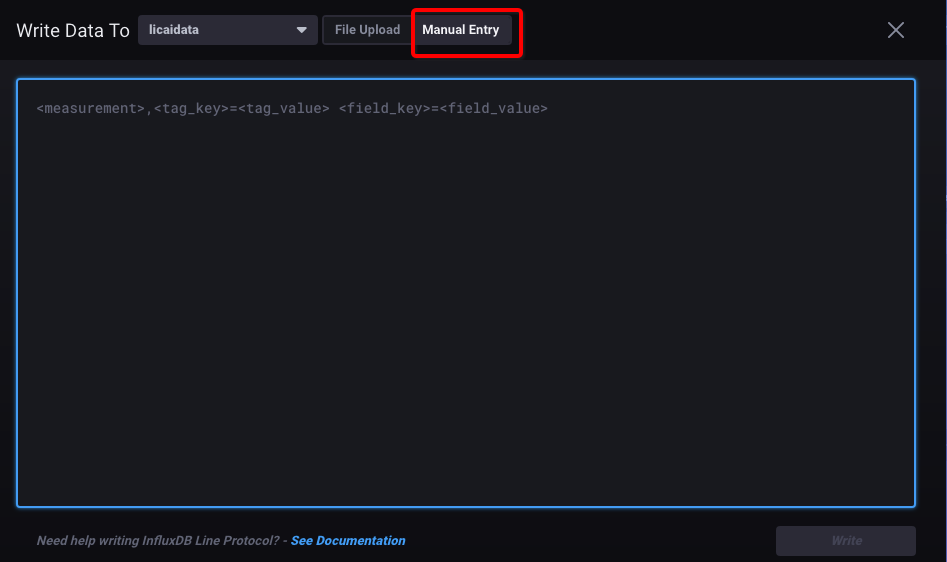
8.3 展示数据(类似Grafana)
1、新增Dashbord
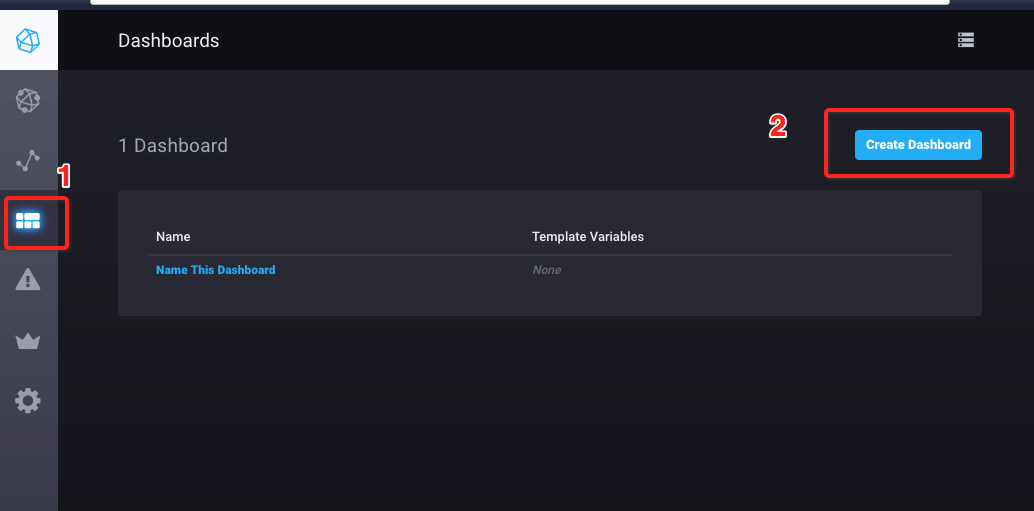
2、 选择如下,
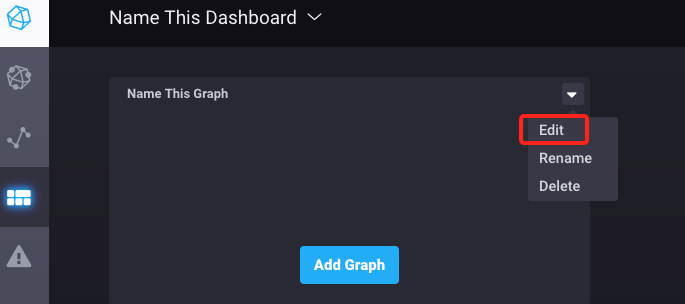
3、通过如下红色区域来创建查询sql
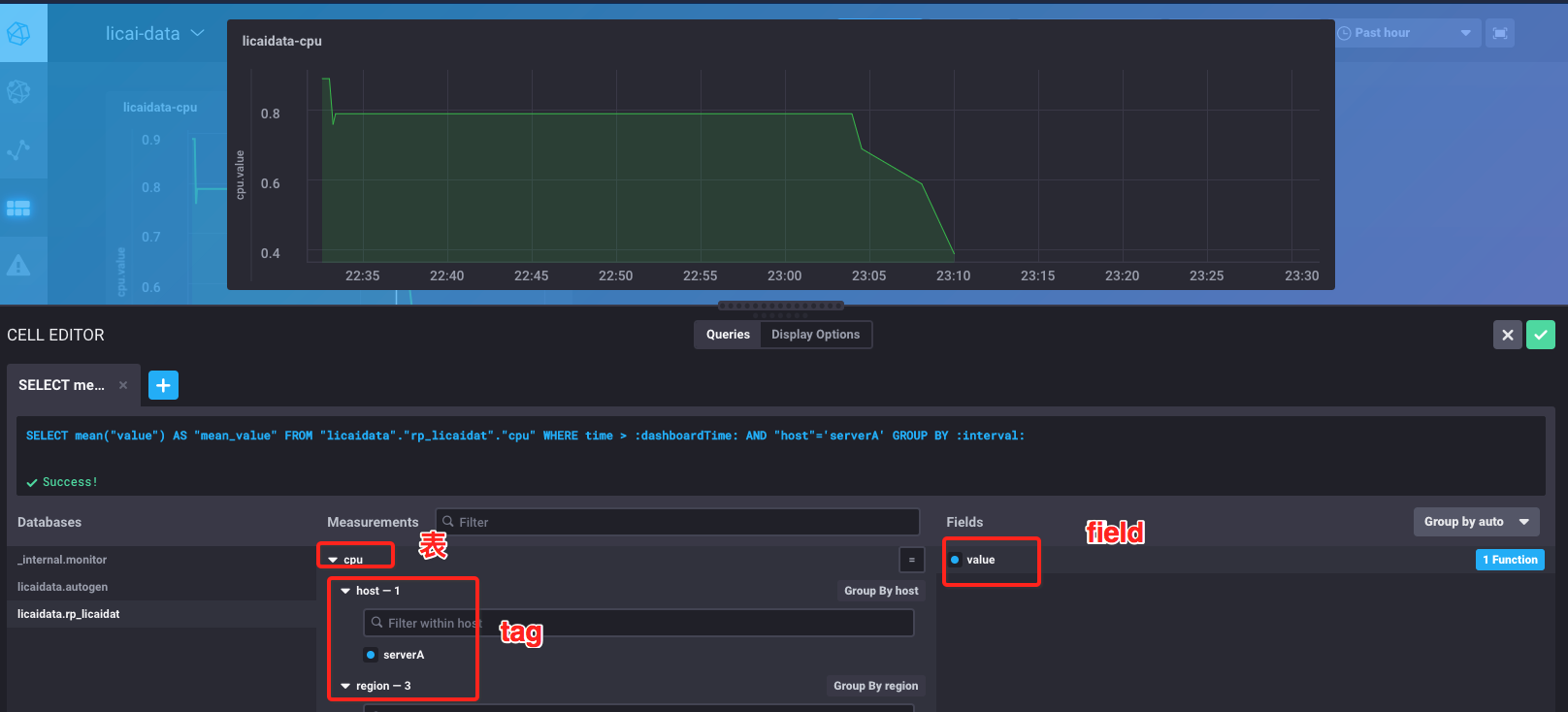
附加
1、influx配置 https://pan.baidu.com/s/1b9BWekHG7aHn5dz_FdLlyA
参考资料
1、influxdb 官方资料 https://docs.influxdata.com/influxdb/v0.9/introduction/getting_started/
2、阿里云influxdb介绍 https://help.aliyun.com/document_detail/113093.html?spm=a2c4g.11186623.6.707.e9765d14M3KQO6





