本文概览:通过“limit statIndex,pageSize”来分页查看数据,如果查询条件(如根据status来过滤数据)在每一次获取之后会更改,那么很容易踩到漏掉数据的坑。
1 问题来了
1、问题描述
假设有一个表字段statues,我们分页获取数据。status初始状态为1,我们分批获取数据,每一批获取1000,对数据进行处理,如果处理成功就更新status为2,否则不更新。通过如下流程来分页获取数据
(1)通过如下sql获取count
|
1 |
select count(1) from table where status =1 |
(2)计算分批个数,其中pageSize是每页个数
|
1 |
int pageCount = count/pageSize + 1; |
(3)分批获取数据
|
1 2 3 4 5 6 7 |
while(pageNow <= pageCount) { // 1.计算 limit的startIndex int startIndex = (pageNow - 1) * pageSize; // 2.通过如下sql获取数据 select * from table where status =1 limit startIndex,pageSize; // 3.对数据进行处理 } |
2、 问题解析
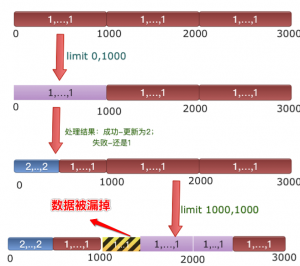
对于上面的代码会漏掉数据,如下图
- 在第一次获取数据limit(0,1000)
1select * from table where status =1 limit 0,1000; - 处理上面的数据,成功的状态更新为2。
- 再次获取数据limit(1000,1000)时,就会漏掉数据
1select * from table where status =1 limit 0,1000;
2 正确做法
使用””limit (pageNow-1)*1000,1000 “方式,如”limit 0,1000” , “limit 1000,2000” , “limit 2000,3000” 分页获取时,如果status没有改变,这种方式是没有问题的,不会漏掉数据。所以我们可以设置startIdex的值为没有改变状态的累加值,如下代码中failcount的值,就是没有没有改变status的累加值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int failCount = 0; while(pageNow <= pageCount) { // 1.pageNow加1 pageNow++; //2.计算 limit的startIndex int startIndex = failCount; // 3.通过如下sql获取数据 select * from table where status =1 limit startIndex,pageSize; // 4.对数据进行处理 if(处理失败){ failcount++; } else{ .... } |
(全文完)




